Tokenomics: the hidden economics of every AI conversation
A single question to Claude Opus costs roughly 2 cents. The same question routed to GPT-4o mini? About 0.04 cents. That's a 50x difference. Welcome to tokenomics.
A single question to Claude Opus costs roughly 2 cents. The same question routed to GPT-4o mini? About 0.04 cents. That's a 50x difference for what might produce an identical answer. Welcome to tokenomics -- the discipline that determines whether your AI-powered product prints money or burns it.
In the old world, work was priced by the hour. You hired a developer at $75/hour, a copywriter at $50/hour, a data analyst at $60/hour. The cost was fixed and predictable. In the new world, work is priced by the token -- fragments of words that models consume as input and generate as output. And this shift changes everything about how we think about productivity, cost, and value.
The cost of GPT-3-level intelligence has dropped 1,000x in three years. Yet total AI spending keeps climbing. Understanding why -- and what to do about it -- is what tokenomics is all about.
What a token actually is (and why it matters more than you think)
A token is roughly three-quarters of a word. "Understanding" gets split into "under" and "standing" -- two tokens. "Cat" is one. Every time you interact with an AI model, two meters are running simultaneously: one counting the tokens you send in (your prompt, your context, your instructions), and another counting the tokens the model generates back.
Here's the part that surprises most people: output tokens cost 3-5x more than input tokens. Sometimes 10x more. This isn't a quirk of pricing -- it reflects the computational reality. Generating new text requires the model to run its full neural network for every single token, while processing input can be parallelized.
Think of it like a restaurant. Reading the menu (input) is free. But every dish the kitchen prepares (output) has a real cost in ingredients, labour, and time. The longer and more elaborate your order, the higher the bill.
This asymmetry is the first law of tokenomics, and it shapes every optimization strategy that follows.
The price of intelligence in 2026
The current AI pricing landscape spans a 2,142x range -- from $0.028 per million tokens (DeepSeek with caching) to $60 per million tokens (OpenAI's o1 reasoning model output). That's like the difference between a bicycle and a private jet, and knowing when to use which is the entire game.
Here's how the major providers stack up:
| Provider | Model | Input (per 1M tokens) | Output (per 1M tokens) | Best for |
|---|---|---|---|---|
| OpenAI | GPT-4o mini | $0.15 | $0.60 | High-volume simple tasks |
| Gemini 2.5 Flash | $0.15 | $0.60 | Speed-critical workloads | |
| DeepSeek | V3 | $0.28 | $0.42 | Budget-conscious teams |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | Fast, capable routing |
| OpenAI | GPT-4.1 | $2.00 | $8.00 | General flagship tasks |
| OpenAI | o3 | $2.00 | $8.00 | Math and science reasoning |
| Anthropic | Claude Sonnet 4.5 | $3.00 | $15.00 | Coding, analysis, writing |
| Anthropic | Claude Opus 4.5 | $5.00 | $25.00 | Complex creative work |
| Gemini 2.5 Pro | $1.25 | $10.00 | Long-context processing |
The table tells a story: there is no single "best" model. There's only the best model for a specific task at a specific price point. Using Opus to classify emails is like hiring a surgeon to put on a plaster. Using GPT-4o mini for architectural design review is like asking an intern to sign off on building plans.
From hourly rates to token rates: the shift nobody prepared for
In the pre-AI world, the economics of work were straightforward. You paid a senior developer $150,000 per year. Roughly $75 an hour. Whether they wrote brilliant code or stared at a blank screen, the meter ran at the same rate. You optimised by hiring better people, improving processes, and reducing meetings.
In the AI-assisted world, the meter runs per token. And this creates a fundamentally different optimisation problem.
Consider a senior developer doing code review. Without AI: two hours per day, $150 in labour cost. With Claude Sonnet handling the initial pass: 45 minutes of developer time plus about $50 per month in API costs. That's $15,200 per year versus $39,000 -- a 156% ROI on the AI investment.
But here's the nuance the productivity claims often miss. A rigorous randomised controlled trial by METR in July 2025 studied experienced open-source developers and found something uncomfortable: while developers perceived a 24% productivity gain from AI tools, their actual measured productivity was 19% slower. The tools helped with boilerplate but introduced new friction points -- reviewing AI suggestions, correcting subtle errors, managing context.
The lesson isn't that AI doesn't help. It's that AI amplifies what you bring to it. On short, well-defined tasks (under two hours), AI systems score 4x higher than human experts. On long, complex tasks (32+ hours), human performance surpasses AI by 2:1. The best tokenomics strategy isn't "use AI for everything" -- it's knowing exactly where the crossover point lies for your specific work.
| Task type | AI advantage | Where the money goes |
|---|---|---|
| Boilerplate code generation | Very high | 50-80% time savings |
| Document summarisation | Very high | 90%+ time savings |
| Data extraction and classification | Very high | 95%+ time savings |
| Translation | High | 70-90% time savings |
| Code review | Moderate-high | 30-50% time savings |
| Novel research | Moderate | 20-40% time savings |
| Complex system architecture | Low | Minimal or negative savings |
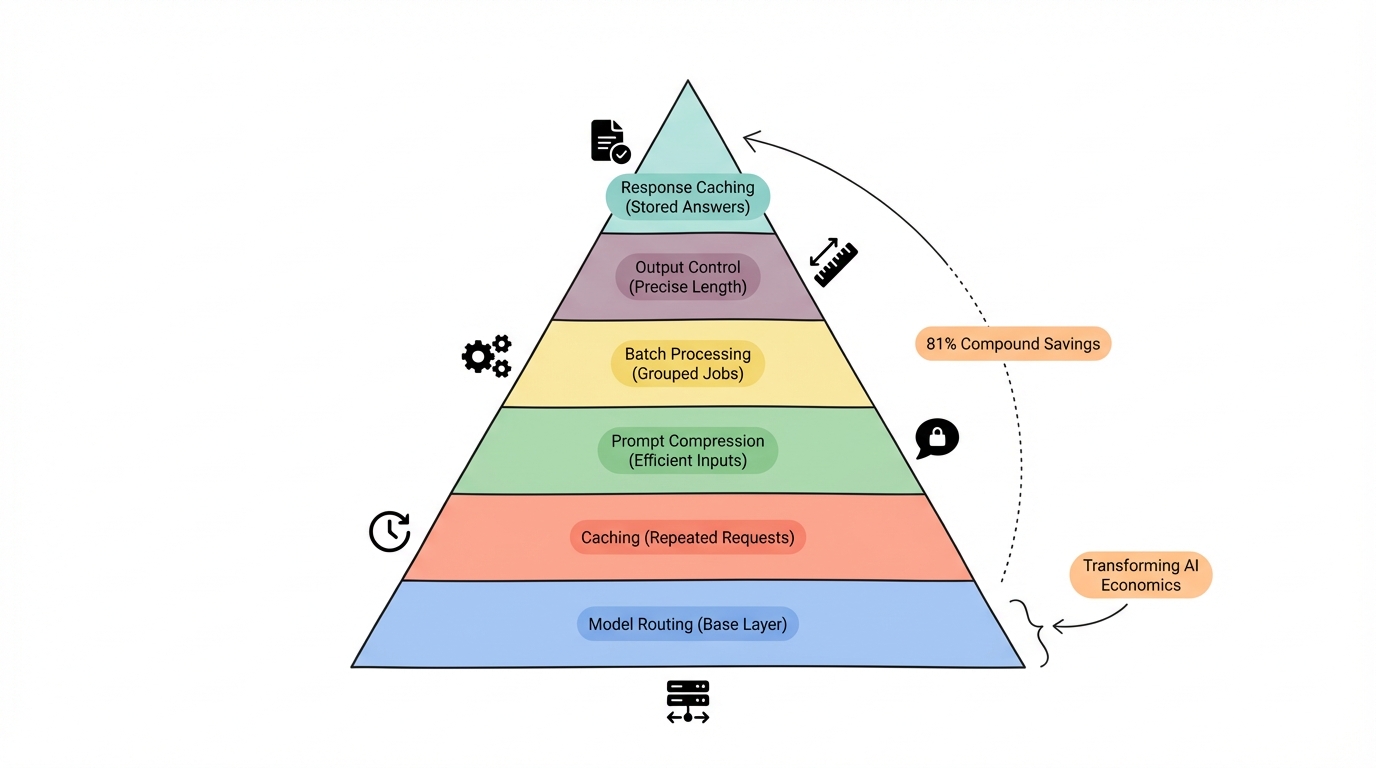
The six strategies that actually reduce your token bill
Optimisation in tokenomics isn't one big lever. It's six smaller levers that compound when used together. A customer support chatbot that implemented all six achieved an 81% cost reduction -- $3,420 per month in savings.
Prompt compression
A verbose 127-token prompt can often be compressed to 38 tokens with identical output quality. That's a 70% reduction just by removing unnecessary words, redundant instructions, and formatting that the model doesn't need.
The rule is simple: write prompts like telegrams, not essays. "Summarize this document in three bullet points" works just as well as "I would like you to please carefully read through the following document and then provide me with a comprehensive summary consisting of three main bullet points that capture the key themes."
Impact: 40-70% token reduction.
Prompt caching
Every major provider now offers caching for the static parts of your prompts. System instructions, few-shot examples, knowledge bases -- anything that doesn't change between requests can be cached.
Anthropic gives you 90% off cached tokens. OpenAI gives 50%. DeepSeek gives 90%. If your system prompt is 2,000 tokens and you send it with every request, caching means you're paying for it once instead of thousands of times.
Impact: 50-90% cost reduction on cached portions.
Model routing
This is the highest-leverage strategy and the one most teams skip. Instead of sending every request to your most capable (and expensive) model, an intelligent router classifies each query and sends it to the cheapest model that can handle it.
Research from RouteLLM (ICLR 2025) shows you can achieve 95% of GPT-4 quality using only 26% GPT-4 calls. The rest go to cheaper models. In practice, this means a system handling 1 million monthly requests can drop from $8,750/month (all frontier) to $1,925/month (routed) -- a 78% reduction with almost no quality loss.
Three approaches exist:
- Rule-based routers: Simple classification by query length or keyword. Fast to implement, less flexible.
- ML-based routers: RouteLLM uses matrix factorisation to predict the optimal model. More accurate, slight overhead.
- LLM-based routers: A tiny, cheap model classifies complexity before routing. Best of both worlds.
Impact: 60-78% cost reduction.
Batch processing
Not everything needs a real-time response. Data labelling, content generation at scale, evaluation pipelines -- these can all use batch APIs that run within a 24-hour window at half the price.
Impact: 50% cost reduction on eligible workloads.
Output control
Since output tokens are the expensive ones, controlling output length is pure savings. Set explicit max_tokens limits. Use stop sequences. Request structured formats like JSON instead of prose. Tell the model "respond in 2-3 sentences" when that's all you need.
Impact: 20-40% output cost reduction.
Response caching
31% of queries to LLMs exhibit semantic similarity to previous requests. A Redis-based semantic cache can intercept these repeat queries and return cached responses without hitting the API at all.
Impact: 15-30% overall cost reduction.
LLMflation: prices are falling, but your bill might not be
Andreessen Horowitz coined the term "LLMflation" to describe a remarkable trend: for an LLM of equivalent performance, the cost decreases by roughly 10x every year. GPT-3 launched at $60 per million tokens in 2021. By 2025, you could get GPT-3-level performance for $0.06 per million tokens.
Epoch AI's analysis is even more dramatic. They found price decline rates ranging from 9x to 900x per year depending on the benchmark, with a median of 200x since January 2024. The price to match GPT-4's performance on PhD-level science questions fell 40x per year.
But here's the paradox. Despite these plummeting unit costs, total AI spending keeps climbing. Google now processes 1.3 quadrillion tokens per month -- a 130x increase in a year. Reasoning models generate roughly 100x more tokens than standard models for the same query. AI agents could drive another 100x increase.
This is Jevons Paradox playing out in real time. When coal became cheaper in 19th-century England, total coal consumption didn't decrease -- it exploded, because cheaper energy opened up use cases that hadn't been economical before. The same is happening with tokens.
The frontier stays expensive too. While last year's capabilities become nearly free, the cutting edge holds steady. OpenAI's o1 reasoning model costs $60 per million output tokens -- the same price GPT-3 launched at. Each new capability tier resets the price clock.
What does this mean practically? Plan for deflation in your tokenomics model. The model you're using today will cost 5-10x less in a year. But resist the temptation to "spend the savings" on more tokens without measuring whether that additional spending produces proportional value.
Where the money is really flowing
Roblox processes 100 billion tokens daily across 70 million users. Through aggressive optimisation -- 2-bit quantisation, speculative decoding, intelligent routing -- they've cut costs by 90%, spending $365,000 per year instead of $3.65 million.
A customer service operation routed 80% of queries to cheap models, reserving expensive ones for the 20% that needed complex reasoning. Result: 75% cost reduction with no measurable decrease in customer satisfaction.
These aren't edge cases. Most organisations implementing comprehensive optimisation achieve 60-90% savings through the layered approach: routing plus caching plus batching plus prompt hygiene.
The enterprises getting this right follow a five-step framework:
- Map usage patterns -- understand which features consume tokens and how frequently
- Estimate token loads -- calculate input/output tokens per interaction type
- Model costs across providers -- compare the same workload across 3-4 models
- Simulate growth -- project what happens at 10x and 100x your current volume
- Set pricing -- ensure your monetisation model accounts for variable AI costs
The companies that skip this step build products where every new user makes them less profitable. Traditional SaaS margins of 70-80% can evaporate to 20-30% when AI costs scale linearly with usage and nobody optimised the token spend.
Thinking about ROI the right way
The average return on generative AI investment is 3.7x for every dollar spent, according to recent industry data. But that average masks enormous variance. The difference between the companies seeing 10x returns and those burning money comes down to one thing: measuring outcomes instead of tokens.
A token is not a unit of value. A useful token is. The cheapest model per token might be the most expensive per useful result if it requires three attempts to get something right, or if a human spends 20 minutes fixing its output.
The formula is straightforward:
AI ROI = (Value Generated - Total AI Cost) / Total AI Cost
But "Total AI Cost" includes more than API bills. It includes development time, integration costs, the human oversight that catches AI mistakes, and the organisational learning curve. And "Value Generated" should measure real outcomes: time saved (multiplied by the hourly rate of the person saved), revenue impact, and error reduction.
Here's a practical example: processing a 500-page legal contract. Gemini 2.5 Flash handles the input for $0.075. Claude Opus processes the same document for $1.25. The Flash model is 17x cheaper. But if Opus catches a critical clause that Flash misses, and that clause saves $50,000 in liability exposure, the "expensive" model just delivered a 40,000x return on its incremental cost.
This is why the smartest tokenomics practitioners don't just optimise for cost. They optimise for cost per useful outcome.
What to do next
Tokenomics isn't a one-time exercise. It's an ongoing practice, like financial planning. Prices change quarterly. New models launch monthly. Your usage patterns evolve as your team gets better at working with AI.
Start here:
If you're just beginning, pick one high-volume task and measure its token consumption. Calculate the cost at three different model tiers. You'll be surprised by the spread.
If you're already using AI at scale, implement model routing. It's the single highest-impact optimisation and most teams haven't done it yet. Even a simple rule-based router that sends short queries to a cheap model can cut costs by 40-60%.
If you're building an AI product, model your tokenomics before you set your pricing. Every customer interaction has a variable cost, and that cost needs to be baked into your unit economics from day one.
The tokens are getting cheaper. The question is whether you'll use that headroom to build something better, or just spend more without thinking about it. The answer to that question is the real tokenomics.
Want more insights?
Subscribe to get the latest articles delivered straight to your inbox.