The Giant Leap to Small: A Guide to Edge AI and SLMs in 2025
The Giant Leap to Small: A Guide to Edge AI and SLMs in 2025For years, the narrative around AI was "bigger is better." We watched parameters balloon from billio...
The Giant Leap to Small: A Guide to Edge AI and SLMs in 2025
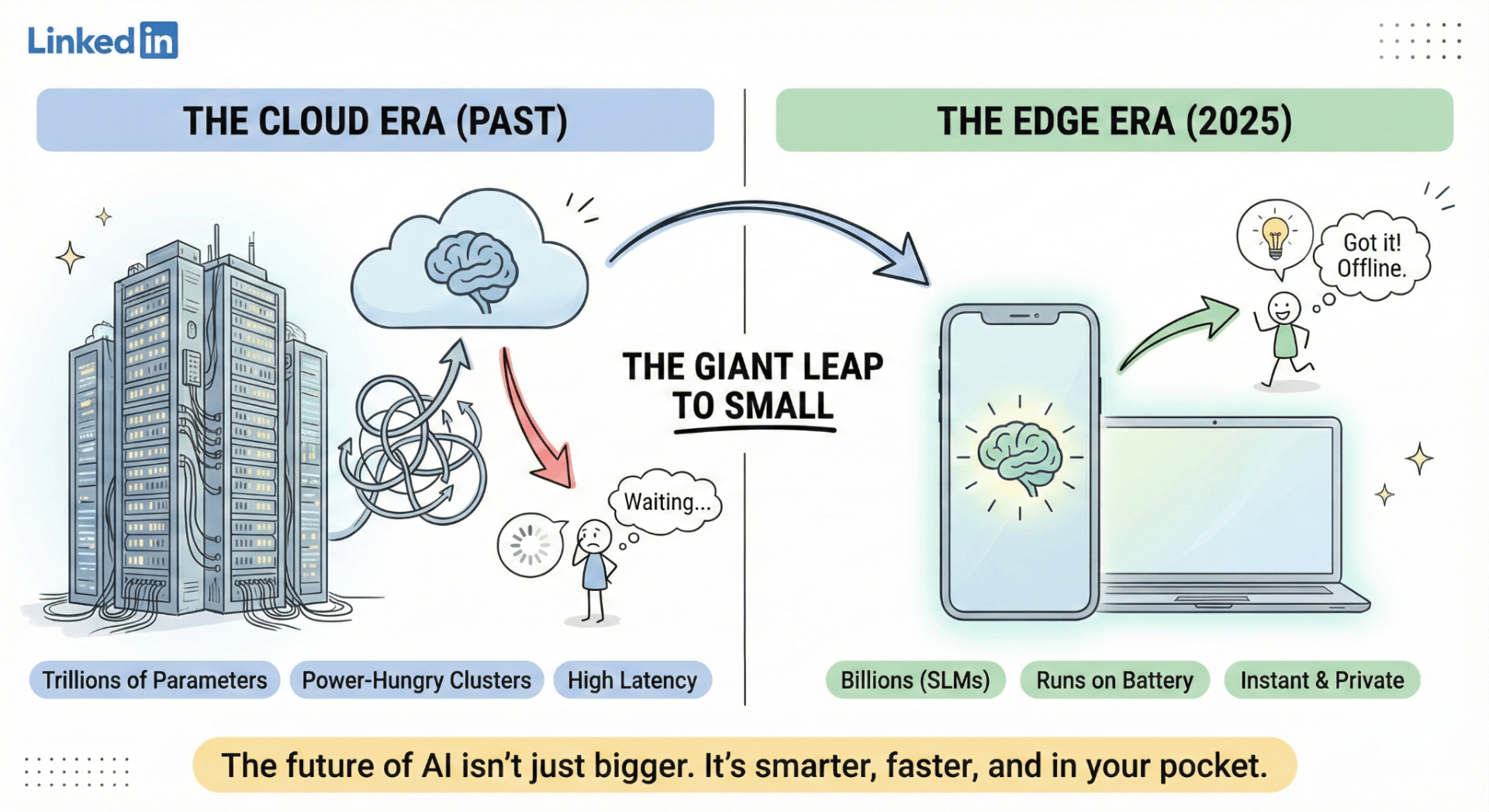
For years, the narrative around AI was "bigger is better." We watched parameters balloon from billions to trillions, with models like GPT-4 and the early Gemini iterations requiring massive data centers to function.
But in 2025, the pendulum has swung. The most exciting frontier in AI isn't the cloud—it’s your pocket.
We are witnessing the rise of Edge AI and Small Language Models (SLMs). These are potent, efficient intelligences designed to run locally on your smartphone, laptop, or even your refrigerator, without sending a single byte of data to the cloud.
Here is a breakdown of the current landscape, the concepts that make it possible, and the models you can run on your device today.
1. The Landscape: LLMs vs. SLMs
To understand where we are, we have to define the two main classes of models dominating the field.
Large Language Models (LLMs)
These are the heavyweights.
- Parameters: Typically 70B to 1T+.
- Hardware: Requires H100/B200 GPU clusters.
- Use Case: Deep reasoning, creative writing, complex coding, and handling massive context windows (millions of tokens).
- Examples: GPT-5 (Cloud), Claude 3.5 Opus, Llama 3.1 405B.
- Status: These remain the "brains" in the cloud for the heaviest lifting.
Small Language Models (SLMs)
These are the "Edge Warriors."
- Parameters: Typically 1B to 10B (though some go as low as 200M).
- Hardware: Runs on consumer GPUs (RTX 4060), Apple Silicon (M4), or even Snapdragon/Tensor mobile chips.
- Use Case: Real-time chat, summarization, privacy-sensitive tasks, and offline assistants.
- Status: Capable of outperforming 2023-era giants (like GPT-3.5) while running on a battery.
2. The Tech Stack: How Do We Fit a Brain in a Phone?
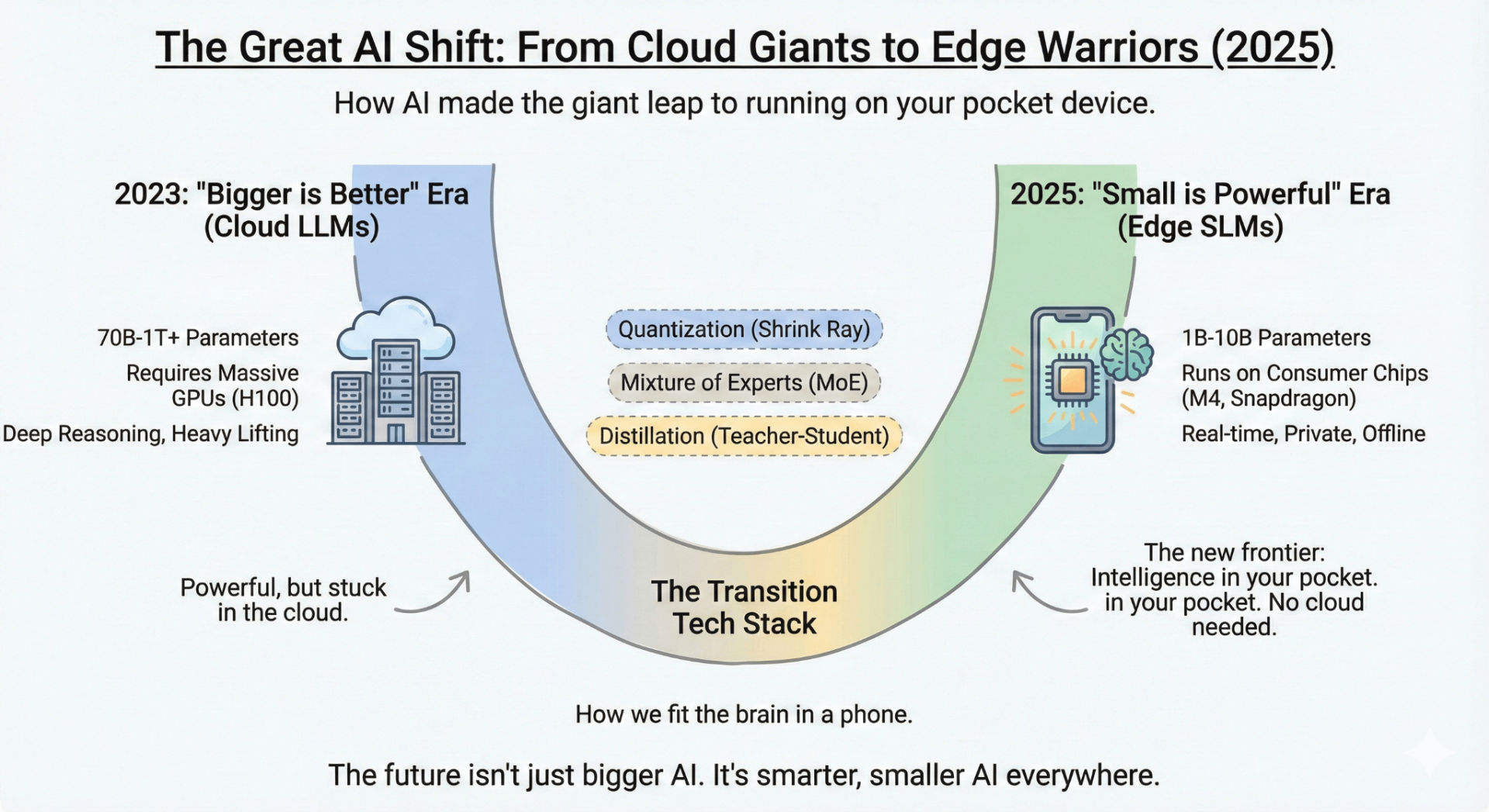
You can’t just shove a cloud model into a phone. It requires specific optimization techniques. These are the concepts you need to know:
A. Quantization (The Shrink Ray)
Models are trained using high-precision numbers (16-bit or 32-bit floating point). Quantization reduces this precision to 4-bit or even 2-bit integers.
- Concept: Imagine rounding $\pi$ from $3.14159265...$ to just $3.14$. You lose a tiny bit of precision but save massive amounts of space.
- Result: A 16GB model can be shrunk to 4GB, allowing it to fit in the RAM of a standard smartphone.
B. Mixture of Experts (MoE)
Instead of one giant dense brain that uses all its neurons for every query, MoE models are composed of several smaller "expert" sub-models.
- Concept: If you ask a math question, only the "Math Expert" neurons activate. The "Poetry Expert" stays asleep.
- Edge Benefit: You might have a model with 40B parameters total, but inference only uses 5B active parameters per token. This makes it blazing fast on mobile chips.
- Example: Mixtral 8x7B.
C. Distillation
This is "teacher-student" learning. A massive model (the teacher) trains a tiny model (the student) by showing it how to reason, effectively transferring its intelligence into a smaller container without the massive computational overhead.
3. The Variants: Models You Can Use on Edge Devices
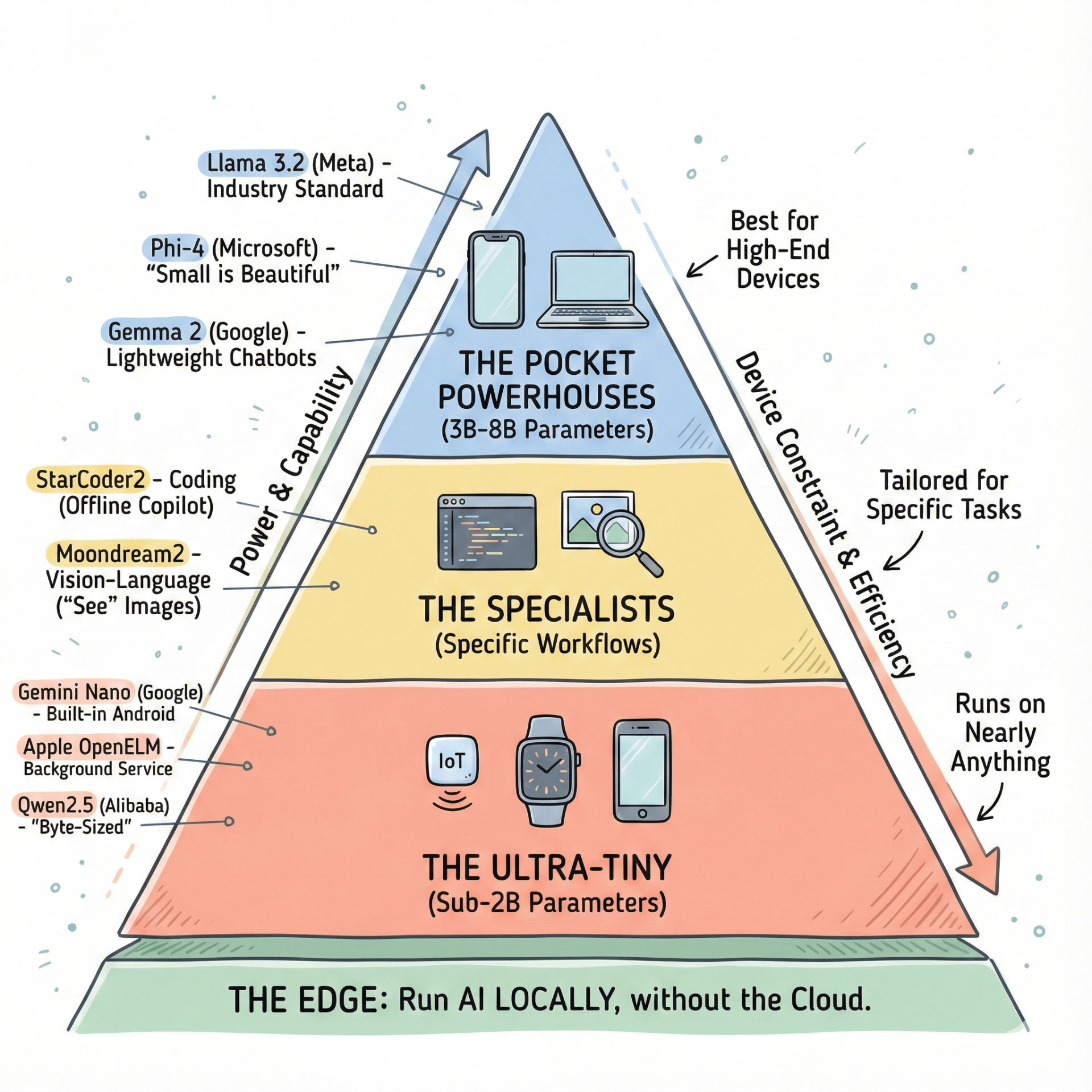
As of late 2025, here are the standout categories and examples of models optimized for edge and mobile deployment.
The "Pocket Powerhouses" (3B - 8B Parameters)
Best for: High-end phones (iPhone 16/17 Pro, Pixel 10) and laptops.
- Llama 3.2 3B & 8B (Meta): The industry standard. The 3B variant is specifically tuned for mobile devices, optimized to run on Arm processors (Qualcomm/MediaTek) with surprising reasoning capabilities.
- Phi-4 (Microsoft): Microsoft’s "small is beautiful" masterpiece. Trained on "textbook quality" data, Phi-4 (and its predecessor Phi-3.5) punches way above its weight class, often beating models 5x its size in logic and math.
- Gemma 2 2B/9B (Google): Built from the same research as Gemini. The 2B version is incredibly lightweight and perfect for basic on-device chatbots.
The "Ultra-Tiny" (Sub-2B Parameters)
Best for: Older phones, IoT devices, Raspberry Pi, and background processes.
- Gemini Nano: Google’s pride, baked directly into Android and Chrome. It handles features like "Smart Reply" and on-device summarization without you even noticing.
- Apple OpenELM (270M - 3B): Highly efficient models released by Apple. The 270M version is so small it can run effectively as a background service on nearly any modern device to handle predictive text or basic classification.
- Qwen2.5-0.5B: A tiny but mighty model from Alibaba. At 0.5 billion parameters, it’s arguably the best "byte-sized" model for simple instruction following on very weak hardware.
The "Specialists"
Best for: Specific workflows.
- Coding: StarCoder2-3B. A model specifically trained on code. It’s small enough to run as a plugin in VS Code on a MacBook Air, offering GitHub Copilot-like features completely offline.
- Vision-Language (VLM): Moondream2. A tiny model that can "see" images. You can run this on a phone to analyze photos (e.g., "What ingredients are in this picture?") without uploading the photo to a server.
4. Real-World Examples: Why Bother?
Why run these on Edge instead of using ChatGPT?
- The "Flight Mode" Writer: Imagine you are on a long-haul flight with no Wi-Fi. With Llama 3 8B running locally on your laptop via software like LM Studio or Ollama, you have a full AI writing assistant that works perfectly offline.
- Privacy-First Health: A health app on your phone uses Gemini Nano to analyze your daily journal entries for signs of stress or burnout. Because the model runs on the phone, your sensitive mental health data never leaves the device.
- The Smart Home Hub: A Raspberry Pi 5 running Phi-3 Mini acts as the brain for your smart home. You can speak complex commands ("Turn off the lights if the TV is on, but only after 8 PM") and it understands the logic locally, without the latency of sending your voice to a cloud server.
Final Thoughts
We have entered the era of Hybrid AI. The cloud will always be there for the "PhD-level" problems, but for the day-to-day interactions—emailing, summarizing, planning, and chatting—the AI will live in your pocket.
Ready to try it? Download Ollama or LM Studio and pull the phi3 or llama3.2:3b model to see the magic on your own machine
Want more insights?
Subscribe to get the latest articles delivered straight to your inbox.