The data is never what they say it is
Enterprise data has two versions: the architecture diagram, and the reality. The gap between the two has derailed more projects than any model failure ever has.
"Our data is clean and in BigQuery. It's ready to go."
I have heard some version of this sentence at the start of every enterprise AI project I have worked on. It has never been true.
Not once.
The call that changes everything
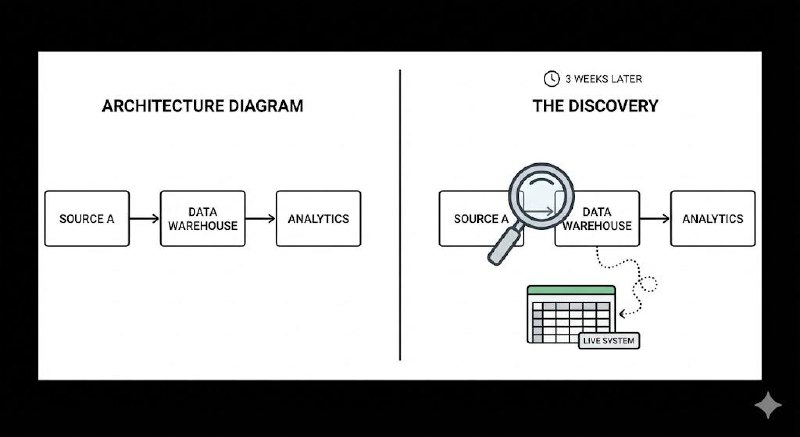
Last year, I started an AI deployment at a large logistics company. Six business units. Eighteen months of planning. A board-level mandate to move fast.
In the kick-off, the data team gave me a walk-through of their architecture. Clean schemas. Documented pipelines. A data warehouse they were visibly proud of.
Three weeks later, I discovered that 40% of the operational data we needed was still living in spreadsheets. Not as a backup. As the live system of record, emailed between teams every morning.
Nobody had mentioned this. Not because they were hiding it. Because to them, it was just how things worked.
Why this happens every time
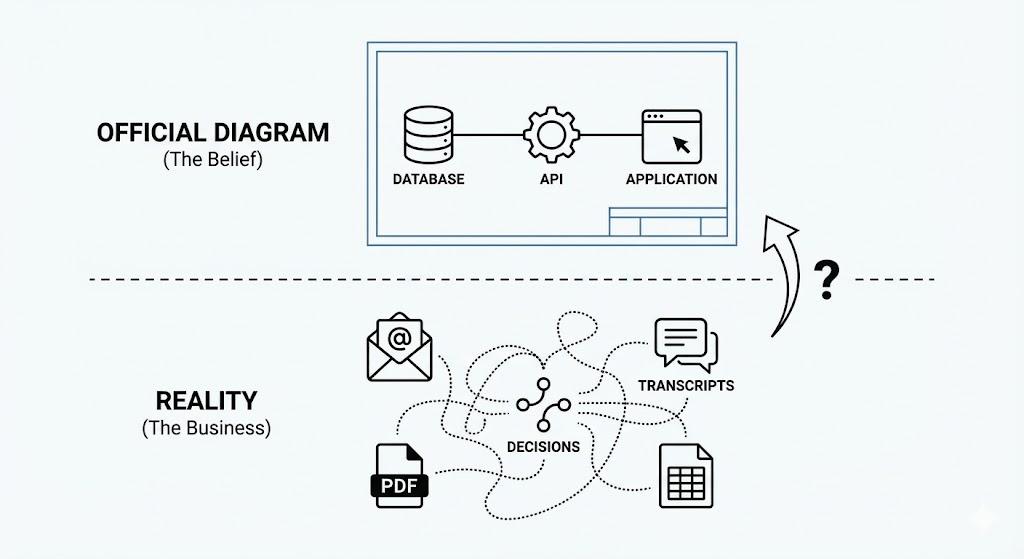
Enterprise data has two versions: the architecture diagram and the reality.
The architecture diagram is what the data team built and what leadership believes is true. The reality is what actually runs the business — the spreadsheet, the shared inbox, the system that was "supposed to be decommissioned in 2021."
These two things coexist. And when an AI project starts, everyone shows you the diagram.
The real data is scattered across unstructured formats. Call transcripts. Email chains. PDFs that have never been parsed. Only 20% of business-critical information in most enterprises sits in structured databases. The other 80% is where actual decisions live. And it is never in the architecture diagram.
I have learned to treat every data conversation as archaeology. You are not finding what exists. You are finding what exists, what was meant to exist, and what stopped existing three years ago but is still referenced everywhere.
The access problem is harder than the quality problem
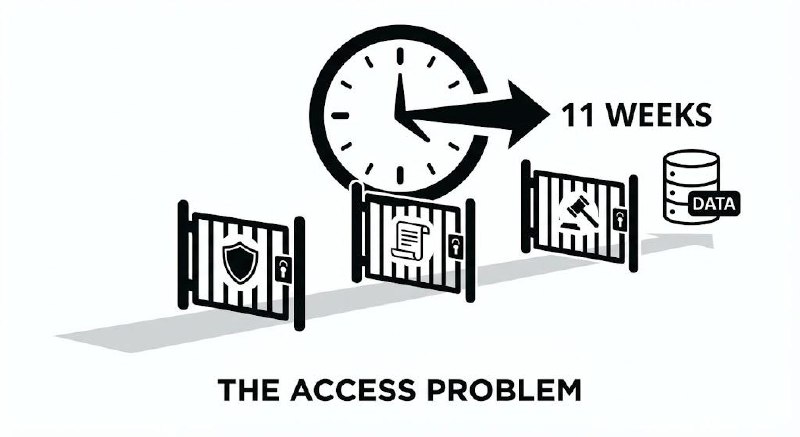
Even when the data is clean and structured, getting to it is not straightforward.
On a deployment at a major infrastructure company, we needed read access to four internal systems to build our first prototype. The data was there. The systems were well-documented. The access request took eleven weeks.
Not because the organisation was obstructionist. Because data access in a large enterprise requires sign-off from the system owner, the information security team, the data governance board, and in regulated environments, a legal review to confirm you are not creating a compliance risk.
Every one of those steps is run by a different person with a different calendar and different priorities.
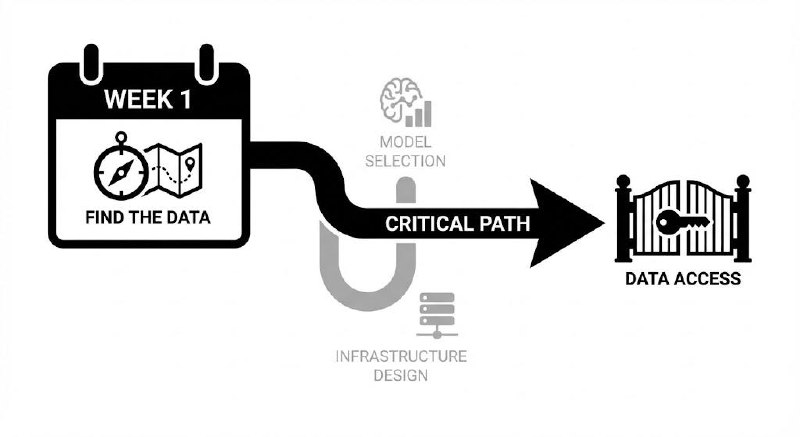
The engineering problem was solved in week one. The access problem ran until week twelve.
What I do differently now
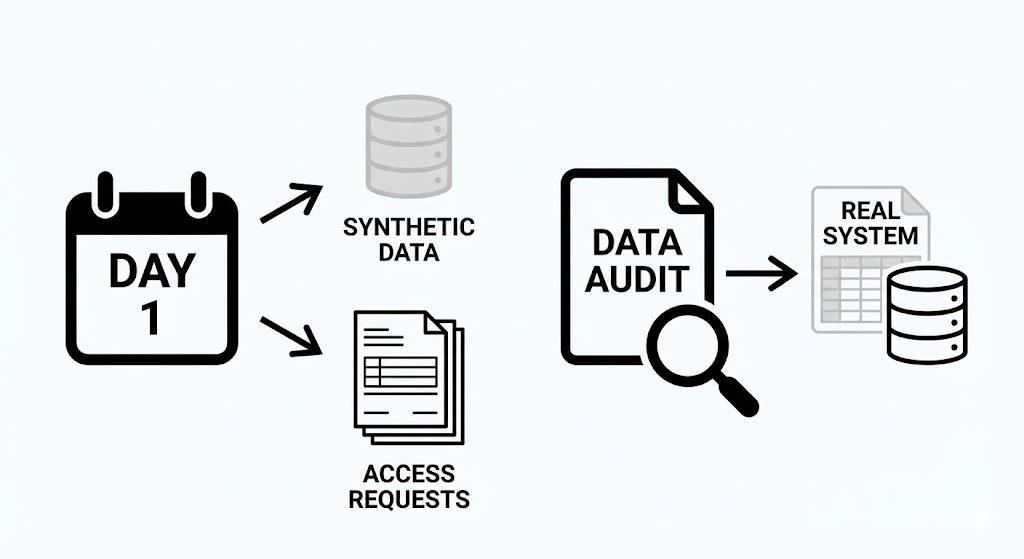
I no longer wait for data access before I start work. I document the data I need, open every access request on day one, and build the first prototype against synthetic data that mirrors what the real system should look like.
When access finally comes through, integration is a configuration change. Not a rebuild.
I also run a data audit in the first two weeks of any engagement. Not to check quality — the team will tell me the quality is fine. To find out what systems the business actually runs on, as opposed to what the data team believes it runs on. Those are almost always different.
The two questions that surface the most useful information:
- "What would you do if your data warehouse went down for a week?" If the answer is "we'd switch to spreadsheets," the spreadsheets are the real system.
- "Where does the data you report to the board actually come from?" The answer to this question is always more complicated than anyone expects.
The pattern I have seen across industries
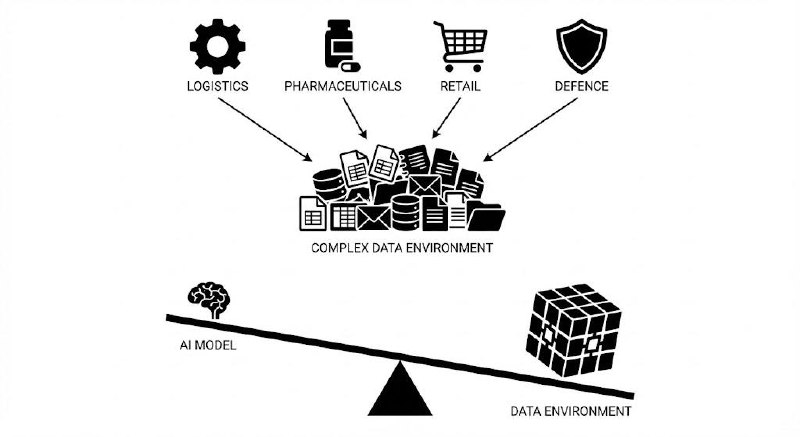
I have run AI deployments at companies in defence, logistics, pharmaceuticals, and retail. The sectors are different. The data problem is always the same.
Not because organisations are careless. Because data accumulates over decades and no organisation has perfect visibility of where it all lives. The system built in 2015 to solve a specific problem becomes load-bearing infrastructure that no one wants to touch. The spreadsheet someone built as a workaround becomes the source of truth.
Enterprise AI projects fail at the data layer more often than they fail at the model layer. The models are remarkably good. The data environments are remarkably complex.
The FDE who understands this is not surprised when the clean data turns out to be messy. They plan for it from the start.
What this means in practice
Want more insights?
Subscribe to get the latest articles delivered straight to your inbox.