MLES Architecture: When Your ML Code is Just the Tip of the Iceberg
Your model training notebook works beautifully. Accuracy looks great. F1 score is solid. Then you push to production and realize the model is maybe 5% of what you actually need to build.
Your model training notebook works beautifully. Accuracy looks great. F1 score is solid. Then you push to production and realize the model is maybe 5% of what you actually need to build.
Welcome to MLES architecture—ML-Enabled Systems that treat machine learning as a distributed systems problem, not just a data science exercise. Since 2022, the field has formalized what companies like Netflix, Uber, and Airbnb learned the hard way: production ML is mostly engineering, with a little bit of modeling sprinkled on top.
The shift matters because how you architect these systems determines whether your ML investment becomes a competitive advantage or technical debt. Let's look at what actually works.
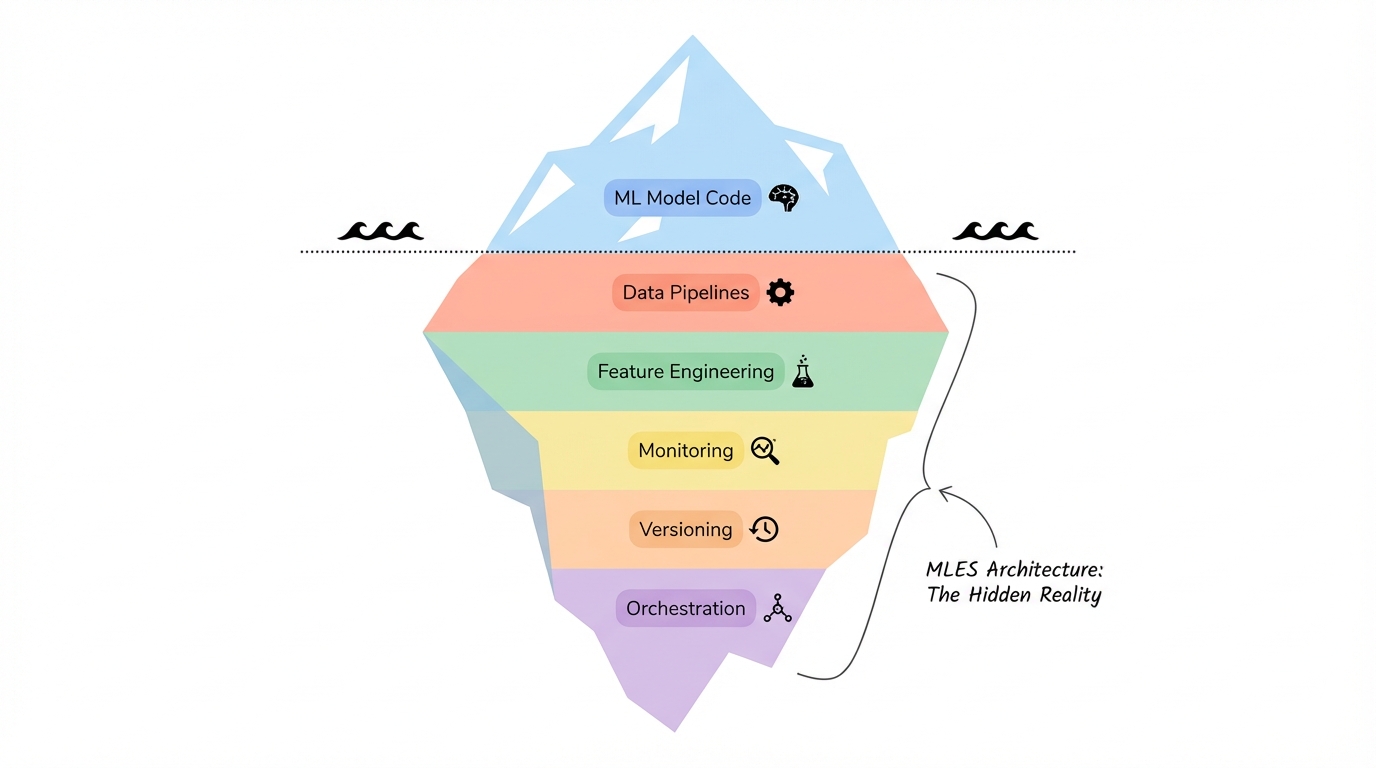
The infrastructure problem nobody talks about
According to the "Hidden Technical Debt in Machine Learning Systems" paper, ML code represents only a small fraction of production systems. The rest is data pipelines, feature engineering, monitoring, versioning, and operational infrastructure.
This isn't a new insight—Google published it years ago. But MLES architecture formalizes the solution. Instead of treating infrastructure as an afterthought, it makes system design the starting point.
Think about a news recommendation engine serving 15,000 users with daily retraining on 144,000 new articles. The model might be 200 lines of PyTorch. But the production system needs Kubernetes for orchestration, Apache Beam for data processing, DVC for versioning, Feast for feature serving, Airflow for workflow management, Prometheus and Grafana for monitoring, and Kong Gateway for API management.
That's not over-engineering. That's the minimum viable stack for keeping the system running without burning out your team.
Why microservices won the ML architecture debate
In 2015, microservices emerged as the dominant pattern for MLES. The reason is simple: ML systems have wildly different scaling requirements across components.
Your model serving endpoint needs low latency and high throughput. Your feature engineering pipeline can run batch jobs overnight. Your monitoring system needs to ingest metrics continuously but doesn't need sub-second response times.
Monolithic architectures force everything onto the same infrastructure. Microservices let you right-size each component.
MLES takes this further with contract-based design. Code contracts define interfaces between services. Model contracts specify input schemas, output formats, and performance SLAs. Data contracts enforce schema validation and lineage tracking.
This sounds like bureaucracy until you've dealt with a model failure caused by a silent schema change three services upstream. Contracts make failures loud and early.
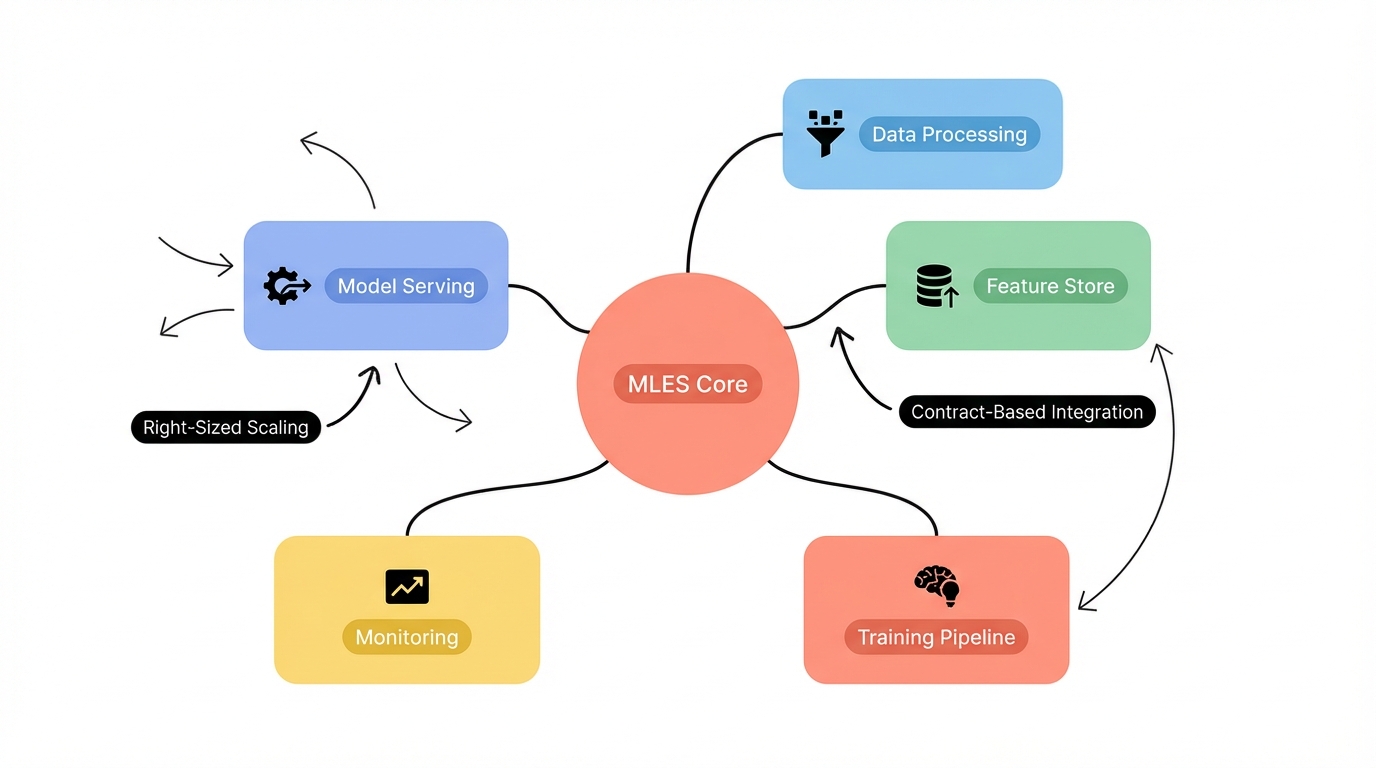
The design patterns that actually matter
Research has identified patterns that show up repeatedly in production ML systems. These aren't theoretical—they're extracted from battle-tested systems at companies shipping ML at scale.
Code-level patterns
Factory Pattern: PyTorch's Dataset class is a factory. You implement __len__ and __getitem__, and the framework handles the rest. Hugging Face took this pattern and added Apache Arrow for zero-copy data access across Python, Pandas, and Spark.
Adapter Pattern: Pandas provides around 20 adapters for reading different file formats. You call read_csv() or read_parquet() and don't think about it. That's the adapter pattern eliminating format hell.
Strategy Pattern: XGBoost lets you swap objective functions and tree construction methods at runtime. Hugging Face pipelines do the same for sentiment analysis, translation, and question-answering. Same infrastructure, different algorithms.
Pipeline Pattern: Scikit-learn's Pipeline chains preprocessing steps with estimators. This isn't just clean code—it enables systematic parameter tuning across the entire workflow. Spark MLlib uses the same pattern for distributed training.
System-level patterns
Proxy Pattern: Cache proxies serve frequent predictions from memory instead of hitting the model every time. This cut inference costs by 60-80% in systems I've worked on. Reverse proxies distribute requests across model replicas for horizontal scaling.
Mediator Pattern: Netflix uses mediator services to coordinate recommendation widgets. The mediator ranks candidates, enforces business rules (minimum items per widget), and deduplicates across sources. Direct service-to-service communication would create a dependency nightmare.
The AWS Well-Architected Framework applied to ML
AWS distilled production ML architecture into five design pillars. These aren't AWS-specific—they apply regardless of where you deploy.
Operational Excellence: Cross-functional teams own the full stack. End-to-end monitoring catches failures before users do. Automated deployment eliminates manual toil.
Security: Access restrictions on data and models. Data governance enforces lineage from source to prediction. You can answer "where did this prediction come from?" in under five minutes.
Reliability: Change management automation prevents bad deploys. Environment consistency means dev, staging, and prod behave the same way.
Performance Efficiency: Right-sized compute for each component. Continuous monitoring catches performance regressions. You optimize for latency or throughput based on actual requirements.
Cost Optimization: Managed services where they make sense. Right-sized instances instead of "just use the biggest GPU." Efficient experimentation prevents burning budget on dead ends.
These pillars force you to answer hard questions early. What happens when the model fails? How do you roll back a bad deploy? How much does each prediction cost?
Choosing between batch, real-time, and near-real-time serving
Architecture selection starts with user experience requirements. Can predictions be precomputed or do they need to be fresh?
Batch serving generates predictions offline and stores them for on-demand retrieval. Content recommendations work this way—Netflix doesn't recompute your homepage every time you refresh. They generate candidates overnight and serve from cache.
Batch serving is simpler and cheaper but can't adapt to real-time signals.
Real-time serving generates predictions on demand. Fraud detection runs this way because you need to flag suspicious transactions before they complete. Real-time means higher latency requirements and more infrastructure complexity.
Near real-time splits the difference. You might update feature stores every few minutes and serve predictions from fresh but not instant data.
The right choice depends on your domain. If you're building a content feed, batch is usually enough. If you're blocking malicious requests, you need real-time. If you're personalizing search results, near real-time probably works.
What production ML actually looks like
Theory is nice. Let's look at what a production system requires.
For a news recommendation system targeting 15,000 users with 144,000 daily articles:
- Infrastructure: Kubernetes for resource management and portability
- Data layer: PostgreSQL for structured data, Apache Beam for stream processing, DVC for dataset versioning
- Feature store: Feast for consistent feature serving across training and inference
- Experiment tracking: Neptune.ai for comparing model runs
- Orchestration: Apache Airflow for scheduling retraining and batch jobs
- Monitoring: Prometheus for metrics, Grafana for dashboards, Elasticsearch for log aggregation
- Deployment: Docker for containerization, Kong Gateway for API management, GitHub Actions for CI/CD
- Serving: Flask or FastAPI for inference endpoints
- Explainability: SHAP for interpreting model decisions
That's not a bloated enterprise stack. It's the minimum for operating reliably without manual intervention.
The contract-based integration layer
MLES architectures use three types of contracts to prevent silent failures:
Code contracts define interfaces between services using OpenAPI specs or Protocol Buffers. When a service changes its API, the contract breaks and you know immediately.
Model contracts specify input schemas, output formats, and performance requirements. If your model expects normalized features between 0 and 1 but gets raw values, the contract catches it.
Data contracts enforce schema validation and lineage tracking. You can trace any prediction back to the exact training data, feature transformations, and model version that produced it.
Contracts add complexity up front but prevent the "works on my machine" scenarios that kill ML projects in production.
Where this is heading
The field formalized in 2022 but adoption is accelerating. Research now documents 35 design challenges, 42 best practices, and 27 architectural decisions specific to ML systems.
This isn't just academic. Companies are extracting patterns from production deployments and sharing them. Mercari open-sourced their ML system design patterns. Uber published Michelangelo. Netflix documented their recommendation architecture.
The trend is toward standardization. Just like web development converged on REST APIs and microservices, ML engineering is converging on MLES patterns.
The next evolution is likely ML-specific infrastructure-as-code. Tools like Terraform and Kubernetes handle general infrastructure well. We need equivalents that understand model registries, feature stores, and A/B testing natively.
We'll also see tighter integration between training and serving. Today these are often separate systems with manual handoffs. The future is continuous training where production feedback directly updates models without human intervention.
Start small, scale deliberately
You don't need the full stack on day one. Start with a simple serving architecture—model, API, monitoring. Deploy it. Watch what breaks.
Then add components as you hit real problems. Feature drift? Add a feature store. Deployment chaos? Add CI/CD. Can't debug predictions? Add lineage tracking.
MLES architecture isn't a checklist. It's a framework for making decisions based on your actual constraints: team size, latency requirements, data velocity, budget.
The model is still important. But if you want it to ship, the architecture matters more.
Want more insights?
Subscribe to get the latest articles delivered straight to your inbox.