Enterprise GenAI : Implementation Blueprint
What McKinsey's Reference Architecture Really Means
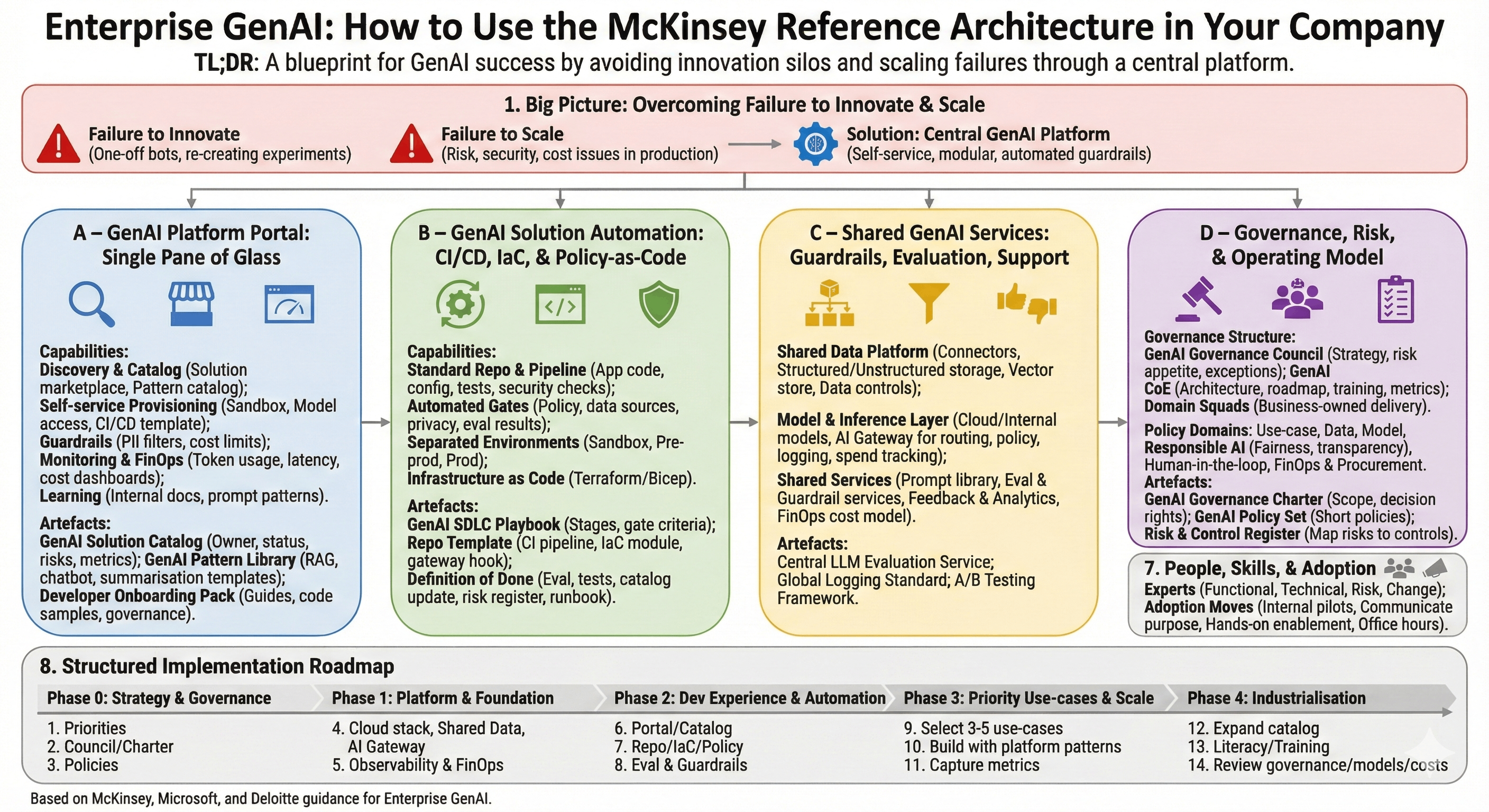
Understanding the McKinsey GenAI Reference Architecture
What McKinsey's Reference Architecture Really Means
McKinsey's work with enterprises reveals two primary failure modes for GenAI programs:
- Failure to Innovate: Teams repeatedly rebuild experiments, wait on compliance approvals, or create one-off solutions that can't be reused
- Failure to Scale: Risk, security, and cost issues kill projects when moving from proof-of-concept to production
Chief information officers and chief technology officers can define reference architectures and integration standards for their organizations. Key elements should include a model hub, which contains trained and approved models that can be provisioned on demand; standard APIs that act as bridges connecting gen AI models to applications or data; and context management and caching, which speed up processing by providing models with relevant information from enterprise data sources.
The Four-Component Platform Architecture
The McKinsey reference architecture breaks down into four interconnected components:
A - Platform Portal: Single entry point with solution catalog and self-service provisioning
B - Solution Automation: CI/CD pipelines with policy-as-code and infrastructure automation
C - Shared Services: AI gateway, prompt libraries, evaluation services, and FinOps
D - Governance & Guardrails: Policies, risk management, lifecycle controls, and data governance
A leading European bank implemented 14 key gen AI components across its enterprise architecture. This approach allowed the bank to implement 80 percent of its core gen AI use cases in just three months.
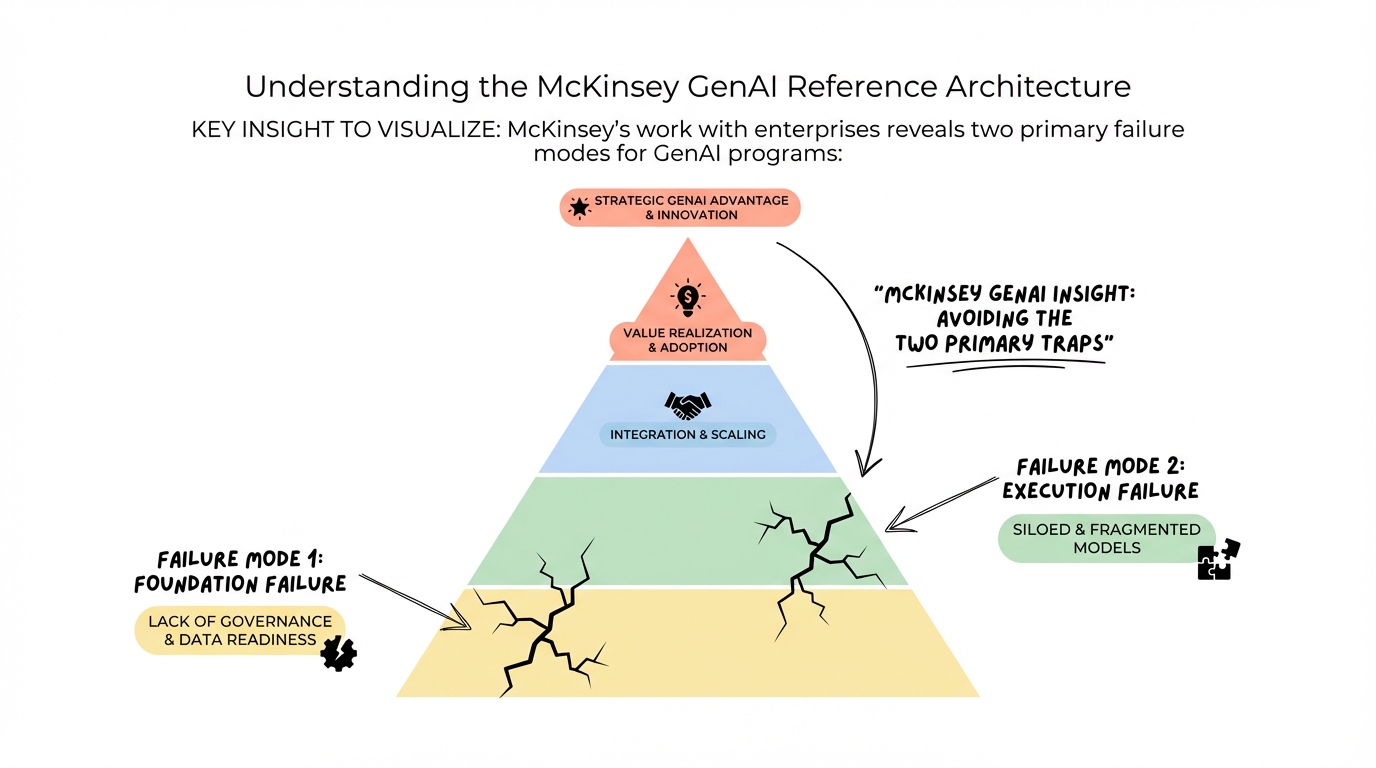
Component A - GenAI Platform Portal
Component A: GenAI Platform Portal - Your Single Pane of Glass
The platform portal serves as the central nervous system for your GenAI operations, providing discovery, provisioning, and monitoring capabilities in one unified interface.
Core Capabilities Required
Discovery & Catalog
- Solution marketplace featuring chatbots, copilots, RAG applications, agents, and approved internal tools
- Pattern catalog with base templates for common archetypes (FAQ bot, knowledge assistant, coding copilot, summarizer, document intake)
- Component library of reusable services (chunking, embeddings, reranking, intent classification)
Self-Service Provisioning
- One-click workspace creation with sandbox environments
- Pre-configured data connections and model access through the AI gateway
- Automated guardrails attachment (PII filters, logging, cost limits)
- Template-based CI/CD pipeline creation
Monitoring & FinOps
This centralized portal can also provide access to gen AI management services, such as observability and analytics dashboards, as well as built-in budget controls and reporting to prevent cost overruns. Making it simple to follow data access controls, track the governance and approval processes, and understand the current state of applications allows the enterprise to operate hundreds of applications with confidence. These controls can be tailored to environments.
Implementation Artifacts
GenAI Solution Catalog
Create a comprehensive catalog (Confluence/SharePoint/Notion or internal web app) documenting:
- Solution owner and business sponsor
- Business value metrics and ROI calculations
- Status (PoC/MVP/Production) with clear promotion criteria
- Models used, data sources accessed, and identified risks
- Usage metrics and user satisfaction scores
GenAI Pattern Library
Develop standardized patterns with:
- RAG (Retrieval-Augmented Generation) applications
- Conversational chatbots and virtual assistants
- Document analysis and summarization pipelines
- Code generation and development assistants
- Agent-based workflow automation
Developer Onboarding Package
- "Start here" guide with access request procedures
- Platform usage tutorials and code samples
- Governance expectations and compliance requirements
- Office hours schedule with the Center of Excellence
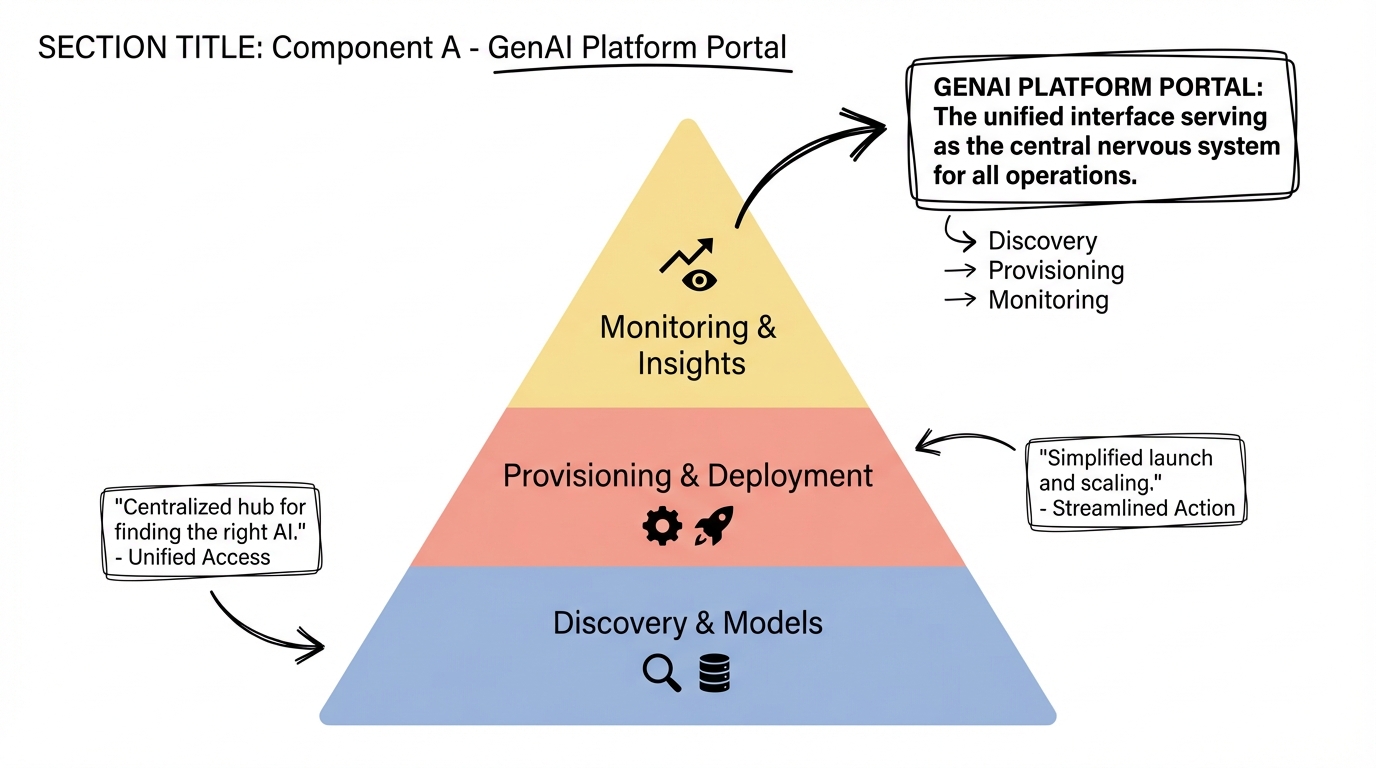
Shared Data and Model Platform
Shared Data & Model Platform: The Foundation Layer
The data and model platform provides the foundational services that all GenAI applications consume, ensuring consistency, quality, and compliance across the enterprise.
3.1 Shared Data Platform
Data Integration Layer
The ability of a business to generate and scale value from gen AI models will depend on how well it takes advantage of its own data. As with technology, targeted upgrades to existing data architecture are needed to maximize the future strategic benefits of gen AI: Be targeted in ramping up your data quality and data augmentation efforts. While data quality has always been an important issue, the scale and scope of data that gen AI models can use—especially unstructured data—has made this issue much more consequential. For this reason, it's critical to get the data foundations right, from clarifying decision rights to defining clear data processes to establishing taxonomies so models can access the data they need. The companies that do this well tie their data quality and augmentation efforts to the specific AI/gen AI application and use case.
Connect enterprise systems including:
- ERP systems (SAP, Oracle, NetSuite)
- CRM platforms (Salesforce, Microsoft Dynamics)
- Collaboration tools (SharePoint, Confluence, Slack)
- File repositories and document management systems
- Real-time data streams and APIs
Storage Architecture
- Structured Data: Tables, data lakes, lakehouse architectures
- Unstructured Data: Documents, emails, PDFs, images, audio, video
- Vector Storage: Embeddings for semantic search and RAG applications
Quality & Governance Controls
- Business and technical metadata in centralized catalog
- Data lineage tracking and impact analysis
- Sensitivity tagging (PII, confidential, regulated)
- Row and column-level security policies
- Automated data quality monitoring and alerting
3.2 Model & Inference Layer
AI Gateway Architecture
The AI gateway serves as the critical control point for all model interactions. The core building blocks of an open architecture are infrastructure as code combined with policy as code so that changes can easily be made at the core and adopted quickly and easily by solutions running on the platform. The libraries and component services offered by the platform should be supported by a clear and standardized set of APIs to coordinate calls on gen AI services. To mitigate risk, manage ongoing compliance, and provide cost transparency, the gen AI platform should implement automated governance guardrails. One example is having microservices that are automatically triggered during specific points along the software development life cycle or solution operations to review code for responsible AI.
Enterprise AI Gateway Options
| Solution | Best For | Key Features | Typical Cost |
|---|---|---|---|
| Kong AI Gateway | Multi-LLM environments | Multi-LLM integrations, Prompt Engineering, Request/Response Transformation, AI analytics | $10-50K/year |
| Azure API Management | Microsoft-centric orgs | Native OpenAI integration, enterprise security | $500-5K/month |
| AWS API Gateway + Lambda | AWS-native architectures | Serverless scaling, tight AWS integration | Pay-per-request |
| NGINX Plus | High-performance needs | Ultra-lightweight, 50K+ transactions per second per node | $2.5-5K/month |
Model Catalog Management
- Foundation Models: OpenAI GPT-4, Claude, Gemini, Llama
- Specialized Models: Code generation, embeddings, vision, audio
- Internal Models: Fine-tuned models for domain-specific tasks
- Model Routing: Automatic selection based on use case, cost, and performance
Current Pricing Landscape (Updated January 2025)
Azure OpenAI Service
Standard (On-Demand): Pay-as-you-go for input and output tokens. Provisioned (PTUs): Allocate throughput with predictable costs, with monthly and annual reservations available to reduce overall spend.
Cost Comparison for 1M Tokens (January 2025)
| Model | Input Cost | Output Cost | Best For |
|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | General purpose, complex reasoning |
| GPT-3.5-Turbo | $0.50 | $1.50 | High-volume, simpler tasks |
| Gemini 2.5 Pro | $1.25 (≤200K context) | $10.00 | Long document analysis |
| Claude 3 Sonnet | $3.00 | $15.00 | Analytical tasks, safety |
Enterprise Volume Discounts: Most providers offer 20-40% discounts for committed spend above $100K annually.
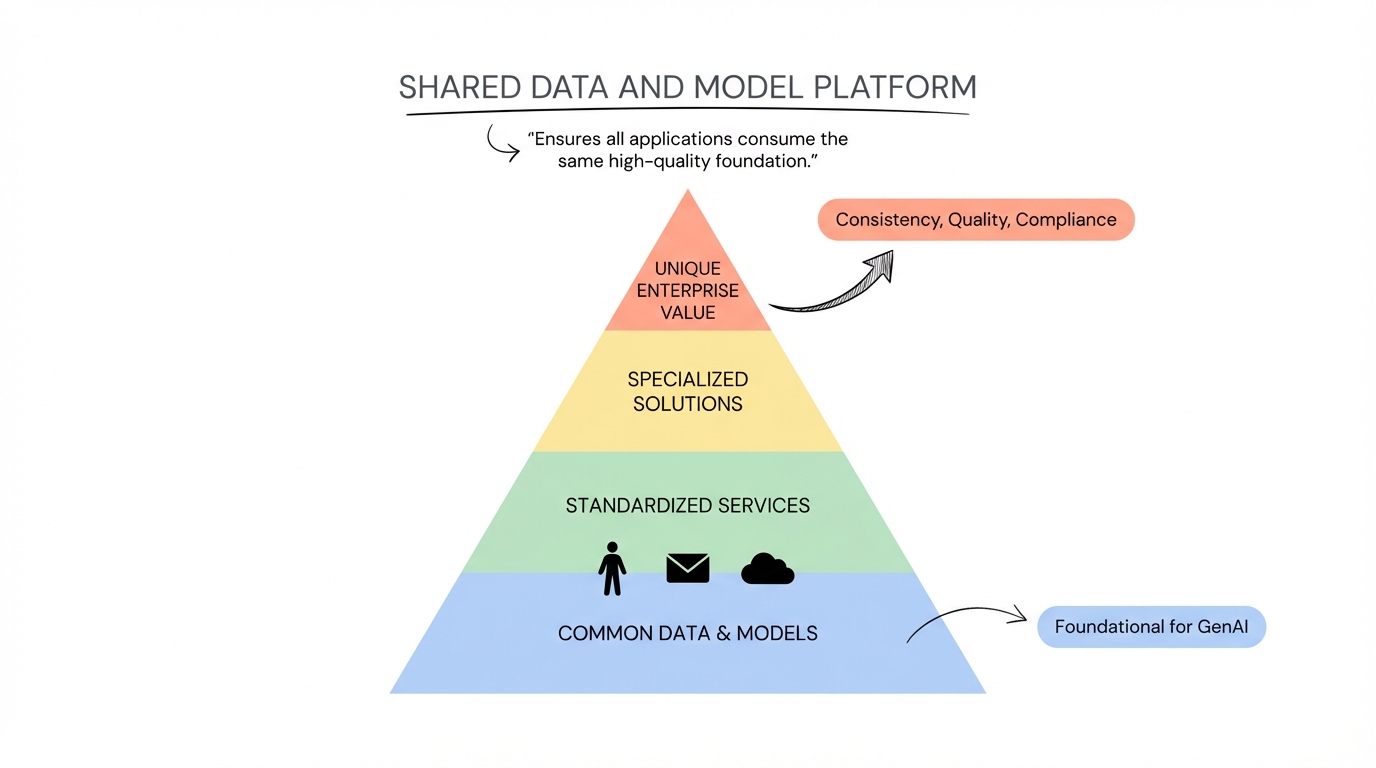
Component B - GenAI Solution Automation
Component B: GenAI Solution Automation - DevSecOps for AI
The core building blocks of an open architecture are infrastructure as code combined with policy as code so that changes can easily be made at the core and adopted quickly and easily by solutions running on the platform. This automation layer ensures every GenAI application follows consistent security, governance, and operational standards.
Core Automation Capabilities
Standard Repository Templates
Every GenAI project starts with a pre-configured repository containing:
- Application code structure (UI + backend + API)
- Model configuration and environment settings
- Gateway endpoint configurations
- Comprehensive test suites (unit, integration, prompt testing, red-team evaluation)
- Security scanning (SAST/DAST, secret detection)
- Infrastructure as Code (Terraform/Bicep/CloudFormation)
Automated Quality Gates
To mitigate risk, manage ongoing compliance, and provide cost transparency, the gen AI platform should implement automated governance guardrails. One example is having microservices that are automatically triggered during specific points along the software development life cycle or solution operations to review code for responsible AI.
CI/CD Pipeline Requirements:
- Policy validation (no direct model keys, gateway-only access)
- Data source approval verification
- Privacy and PII usage compliance checks
- Model evaluation results above defined thresholds
- Cost impact assessment and approval gates
Environment Strategy
- Sandbox: Fast iteration, generous token limits, minimal guardrails
- Pre-production: Full security controls, staging data, performance testing
- Production: Strict governance, change management, monitoring
GenAI-Specific Testing Framework
Prompt Testing
- Regression testing for prompt changes
- A/B testing framework for prompt optimization
- Consistency testing across model versions
- Edge case and adversarial prompt testing
Model Evaluation Pipeline
- Accuracy assessment against golden datasets
- Bias detection and fairness testing
- Hallucination detection for RAG applications
- Performance benchmarking (latency, throughput)
Implementation Standards
Definition of Done for GenAI Changes
- Automated tests pass (including prompt regression tests)
- Model evaluation scores meet minimum thresholds
- Security scans show no high/critical vulnerabilities
- Documentation updated (runbooks, model cards, risk assessments)
- Cost impact assessed and approved
- Governance review completed for production deployments
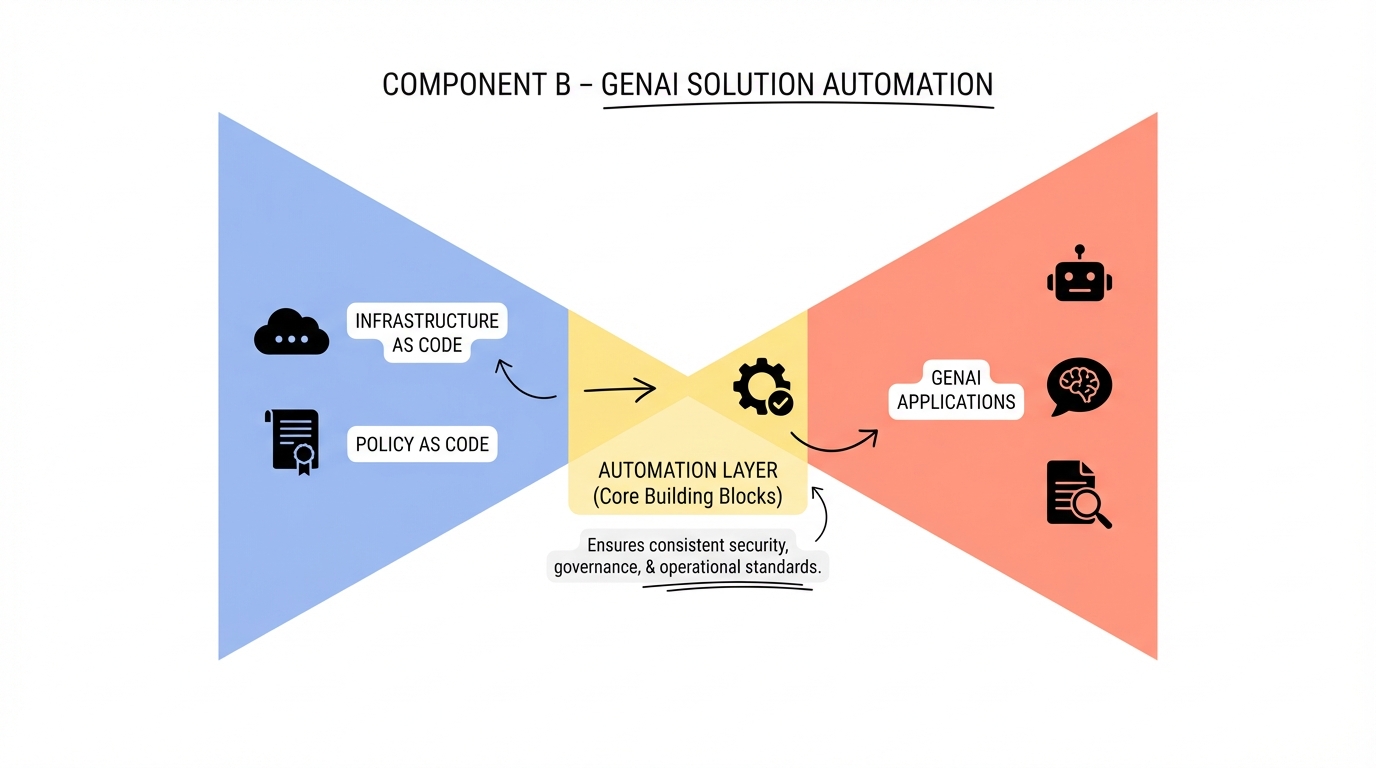
Component C - Shared GenAI Services
Component C: Shared GenAI Services - The Reusability Engine
The key to scale in tech is maximizing reuse. Enabling reuse relies on developing an open modular architecture that is able to integrate and easily swap out reusable services and capabilities. This open-architecture approach can also dramatically reduce the total cost of ownership. Leading enterprises focus on developing two sets of reusable capabilities: the complete gen AI application patterns for common archetypes (such as knowledge management, customer chatbot, or agentic workflows) and data products (for example, RAG and GraphRAG) and the common libraries used in most gen AI applications.
Core Shared Services Architecture
1. Prompt Library & Engineering Services
- Pre-approved prompt templates by department (HR, Legal, Finance, Engineering)
- Multi-language prompt variants and localization
- Prompt version control and rollback capabilities
- Performance analytics and optimization recommendations
2. Evaluation & Safety Services
- Content Safety: Toxicity, bias, harmful content detection
- Privacy Protection: PII detection and redaction services
- Hallucination Detection: Fact-checking against source documents for RAG
- Policy Compliance: Custom rule engines for industry regulations
3. Common AI Libraries
Available as microservices with standardized APIs:
- Text Processing: Chunking, tokenization, preprocessing
- Embeddings: Multiple model options (OpenAI, Cohere, sentence-transformers)
- Retrieval: Semantic search, reranking, query enhancement
- Intent Classification: Route user queries to appropriate handlers
4. Analytics & Observability
- Usage Analytics: Token consumption, model performance, user patterns
- Cost Attribution: Per-application, per-team, per-use-case tracking
- Quality Metrics: User satisfaction, task completion rates, error analysis
- A/B Testing: Experiment framework for prompts, models, and flows
Real-World Service Examples
LangChain Integration with Kong AI Gateway
With the base_url parameter, we can override the OpenAI base URL that LangChain uses by default with the URL to our Kong Gateway Route. This way, we can proxy requests and apply Kong Gateway plugins, while also using LangChain integrations and tools.
from langchain_openai import ChatOpenAI
# Route through enterprise AI gateway
llm = ChatOpenAI(
base_url="https://ai-gateway.company.com/v1",
model="gpt-4o",
api_key="enterprise-token"
)
FinOps & Cost Management
Implement enterprise cost controls:
- Budget alerts and hard limits per team/project
- Usage forecasting based on historical patterns
- Model cost comparison and automatic optimization
- Charge-back reporting for business units
McKinsey's Lilli Platform Insights
McKinsey's development of its internal GenAI platform, named Lilli, provides valuable insights into how large enterprises can successfully implement practical solutions while prioritizing user adoption and maintaining high security and quality standards. McKinsey's approach to developing Lilli is noteworthy for its methodical, user-centric implementation strategy. Starting with a small team of just four people that has since grown to over 150, the firm focused on solving specific operational challenges across four key domains: team performance, client development, service delivery, and post-project communications.
Rather than simply implementing a retrieval-augmented generation (RAG) system, they created a sophisticated orchestration layer that combines large and small models. This architecture enables the platform to maintain McKinsey's distinctive voice and quality standards while providing secure access to nearly a century of the firm's intellectual property.
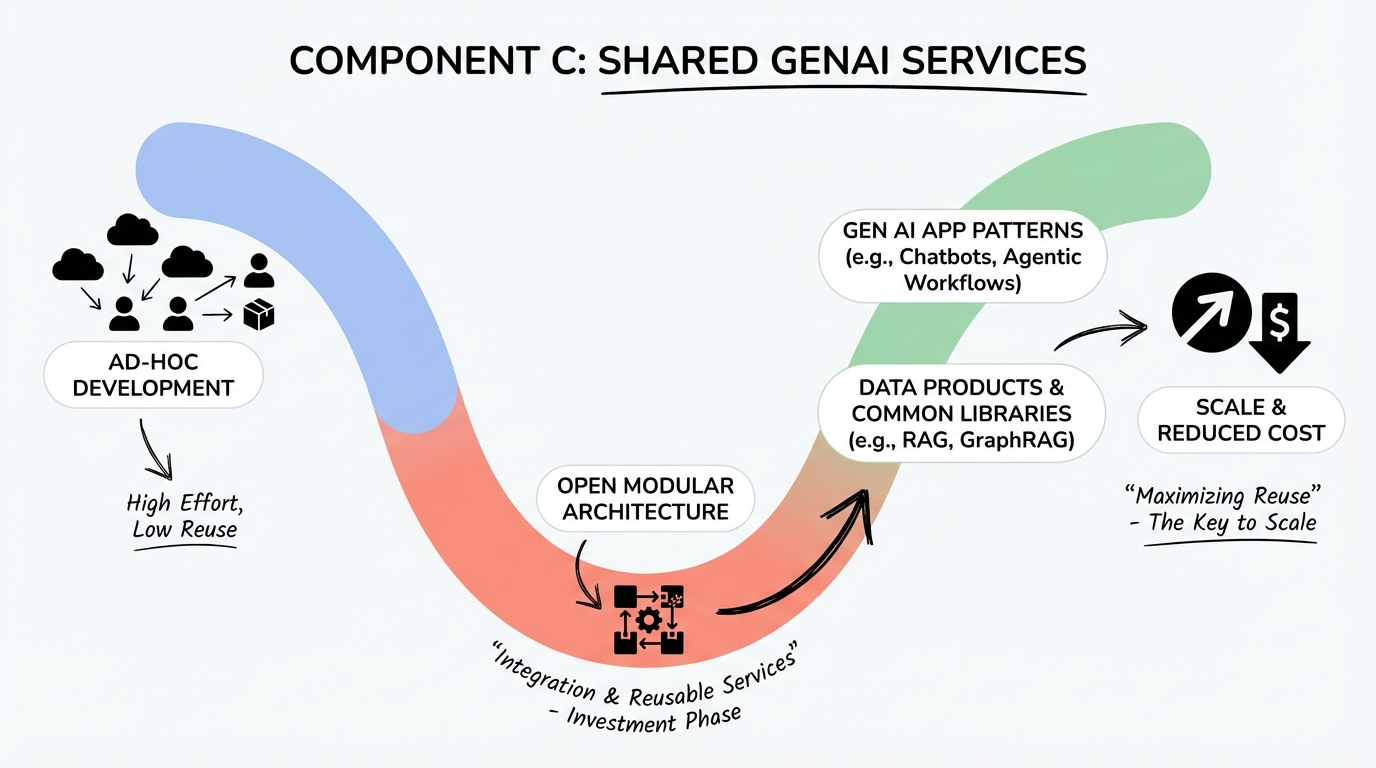
Component D - Governance and Operating Model
Component D: Governance, Risk, and Operating Model
A data management and governance strategy should be part of any operating model for gen AI. Governance includes managing document sourcing, preparation, curation, and tagging, as well as ensuring data quality and compliance, for both structured and unstructured data.
Governance Structure Framework
GenAI Governance Council
- Executive Sponsor: CIO, CDO, or Chief Digital Officer
- Cross-functional Members: IT, Data, Security, Risk, Legal, HR, Communications
- Key Responsibilities:
- Define AI principles and risk appetite
- Approve governance policies and standards
- Prioritize use cases and resource allocation
- Handle exceptions and escalations
GenAI Center of Excellence (CoE)
Core team responsibilities:
- Platform architecture and development standards
- Pattern library creation and maintenance
- Training and enablement programs
- Metrics collection and success measurement
- Risk assessment and mitigation strategies
Essential Policy Domains
1. Use Case Policy
- Prohibited use cases (external AI for confidential data)
- Risk-based approval criteria (low/medium/high risk categories)
- Value assessment framework (ROI, strategic alignment, feasibility)
2. Data Governance for AI
Managing vast amounts of unstructured data, which comprise more than 80 percent of companies' overall data, may seem like a daunting task. Indeed, 60 percent of gen AI high performers and 80 percent of other companies struggle to define a comprehensive strategy for organizing their unstructured data.
Essential data controls:
- Data classification for AI use (public, internal, confidential, restricted)
- PII handling and anonymization requirements
- Data retention policies for prompts and responses
- Cross-border data transfer restrictions
3. Model Management Policy
- Approved model catalog with use case mapping
- Model evaluation standards and testing requirements
- Fine-tuning governance and approval processes
- Model lifecycle management (deployment, monitoring, retirement)
4. Responsible AI Framework
Core principles implementation:
- Fairness: Bias testing and mitigation procedures
- Transparency: Model cards and decision explanations
- Accountability: Clear ownership and decision rights
- Robustness: Adversarial testing and failure handling
- Privacy: Data minimization and user consent management
Implementation Roadmap
Phase 0: Foundation (0-3 months)
- Establish Governance Council and Center of Excellence
- Define initial policy set (5-7 core policies)
- Conduct AI readiness assessment
- Select initial use cases and pilot teams
Phase 1: Platform Core (3-6 months)
- Deploy shared data platform and AI gateway
- Develop standardized tooling and infrastructure where teams could securely experiment and access a GPT LLM, a gateway with preapproved APIs that teams could access, and a self-serve developer portal
- Implement basic observability and cost tracking
- Train initial developer cohort
Phase 2: Scale & Standardize (6-12 months)
- Complete portal and automation capabilities
- Deploy shared services library
- Build evaluation and safety services
- Expand to 5-10 production use cases
Phase 3: Enterprise Deployment (12-18 months)
- Roll out to all business units
- Implement advanced governance and compliance
- Optimize costs and performance
- Measure and communicate business value
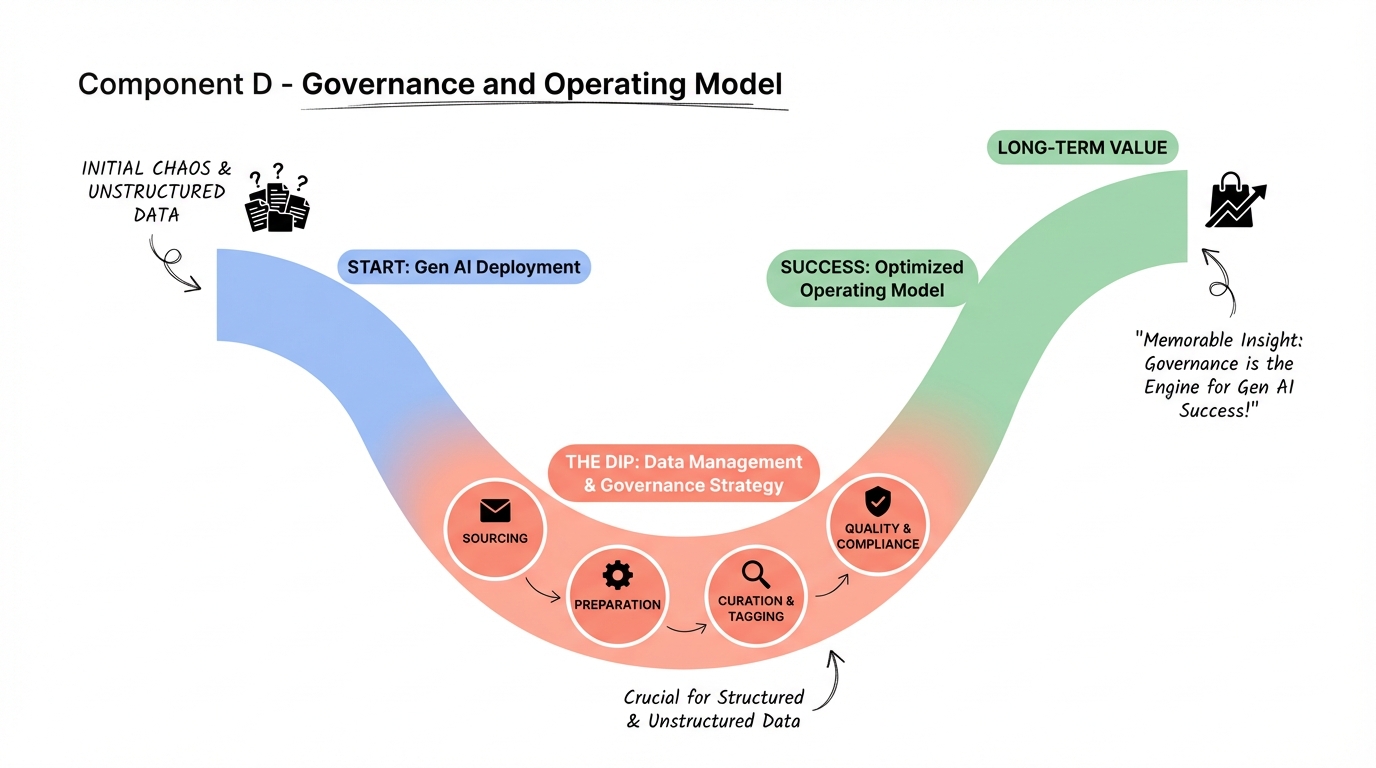
Real-World Implementation Examples
Real-World Implementation Examples
European Bank Case Study
A leading European bank implemented 14 key gen AI components across its enterprise architecture. This approach allowed the bank to implement 80 percent of its core gen AI use cases in just three months. By identifying the gen AI components with the largest potential impact early on, the bank focused its developer resources to produce gen AI features aligned with clear mid- to long-term goals.
Key Success Factors:
- Component-based architecture from day one
- Focus on reusable capabilities rather than point solutions
- Clear prioritization based on business impact
- Developer resources concentrated on platform capabilities
Multi-Cloud AI Gateway Implementation
Technology Stack Example:
- AI Gateway: Kong Gateway with AI plugins
- Vector Database: Redis for semantic search and caching
- Model Providers: Azure OpenAI (primary), AWS Bedrock (backup), Google Vertex (specialized)
- Orchestration: Kong AI Gateway and Redis can collaborate for AI-based apps using frameworks like LangChain and LangGraph
Architecture Benefits:
- Kong AI Gateway normalizes the consumption of any LLM infrastructure, including Amazon Bedrock, Mistral, OpenAI, Cohere, etc
- Vendor independence and negotiating power
- Automatic failover and load balancing
- Centralized cost and usage tracking
Enterprise Cost Optimization Results
Before Platform Implementation:
- 15+ separate GenAI experiments
- $45K monthly token costs
- 3-6 month time-to-production
- Limited reusability across projects
After Platform Implementation (12 months):
- 40+ production use cases using shared components
- $28K monthly token costs (38% reduction despite 3x more use cases)
- 2-4 week time-to-production for new use cases
- 85% component reuse rate across applications
Technology Selection Decision Matrix
Technology Selection Decision Matrix
Cloud Platform Comparison
| Platform | Best For | Strengths | Pricing Model | Enterprise Features |
|---|---|---|---|---|
| Azure OpenAI | Microsoft-integrated environments | Smoothest if you're a Microsoft shop. The integration with Teams and Power Platform is genuinely impressive for internal tools | GPT-4o: $2.50/$10.00 per 1M tokens | Enterprise agreements, compliance certifications |
| AWS Bedrock | Model diversity and AWS integration | Multiple model providers, strong enterprise controls | Variable by model | Provisioned Throughput for large workloads |
| Google Vertex AI | Massive context windows, multimodal | 2M context window is a game-changer for document-heavy applications, and the free tier is perfect for prototyping | Gemini 2.5: $1.25/$10.00 per 1M tokens | BigQuery integration, AutoML capabilities |
AI Gateway Selection Criteria
For Microsoft-Heavy Organizations: Azure API Management + Application Gateway
- Native integration with Azure OpenAI
- Existing enterprise agreements
- Teams and Power Platform connectivity
For Multi-Cloud/Multi-Model Strategies: Kong AI Gateway
- Multi-LLM capability allows the AI Gateway to abstract Amazon Bedrock (and other LLMs as well) load balancing models based on several policies including latency time, model usage, semantics etc
- Vendor independence
- Advanced routing and transformation capabilities
For AWS-Native Architectures: API Gateway + Lambda + Application Load Balancer
- Serverless scaling
- Deep AWS service integration
- Cost-effective for variable workloads
Build vs. Buy Analysis
Build Internal Platform When:
- Unique compliance or security requirements
- Existing strong platform engineering team
- Long-term competitive differentiation through AI
- Budget >$2M annually for platform development
Buy/Partner When:
- Need faster time-to-market (3-6 months vs. 12-18 months)
- Limited platform engineering resources
- Standard enterprise requirements
- Focus on use case development over platform building

Cost Analysis and ROI Framework
Cost Analysis & ROI Framework
Total Cost of Ownership (TCO) Breakdown
Platform Infrastructure Costs
- AI Gateway: $10-50K annually (depending on scale)
- Vector Database: $500-5K monthly (Redis/Pinecone/Weaviate)
- Monitoring & Analytics: $200-2K monthly
- Development Tools: $50-500 per developer monthly
Model Usage Costs (Monthly for 10M tokens)
- GPT-4: ~$35K
- GPT-3.5 + GPT-4 Mix: ~$15K
- Open Source Models (hosted): ~$5K infrastructure + compute
Personnel Costs (Annual)
- Platform Team (4-6 people): $800K-1.2M
- GenAI Engineers (per person): $120-180K
- Training & Enablement: $50-100K annually
ROI Calculation Framework
Productivity Gains
- Developer productivity: 20-30% improvement
- Content creation: 40-60% time savings
- Document processing: 70-85% time reduction
- Customer support: 30-50% efficiency gains
Cost Avoidance
- Reduced external consulting: $200-500K annually
- Faster time-to-market: $100-300K per quarter
- Operational efficiency: 15-25% cost reduction in target processes
Revenue Enhancement
- New product capabilities: 5-15% revenue uplift
- Improved customer experience: 10-20% satisfaction improvement
- Market differentiation: Quantify competitive advantages
Break-Even Analysis
Typical Enterprise Scenarios:
Small Enterprise (100-500 employees)
- Platform cost: $150K annually
- Break-even: 2-3 major use cases with 20%+ efficiency gains
Mid-Market (500-2,000 employees)
- Platform cost: $400K annually
- Break-even: 5-8 use cases with 25%+ productivity improvements
Large Enterprise (2,000+ employees)
- Platform cost: $800K-1.5M annually
- Break-even: 15+ use cases with 20%+ efficiency gains
Key Success Metrics:
- Time-to-production for new GenAI use cases
- Developer satisfaction and adoption rates
- Cost per successful use case deployment
- Business value delivered per dollar invested

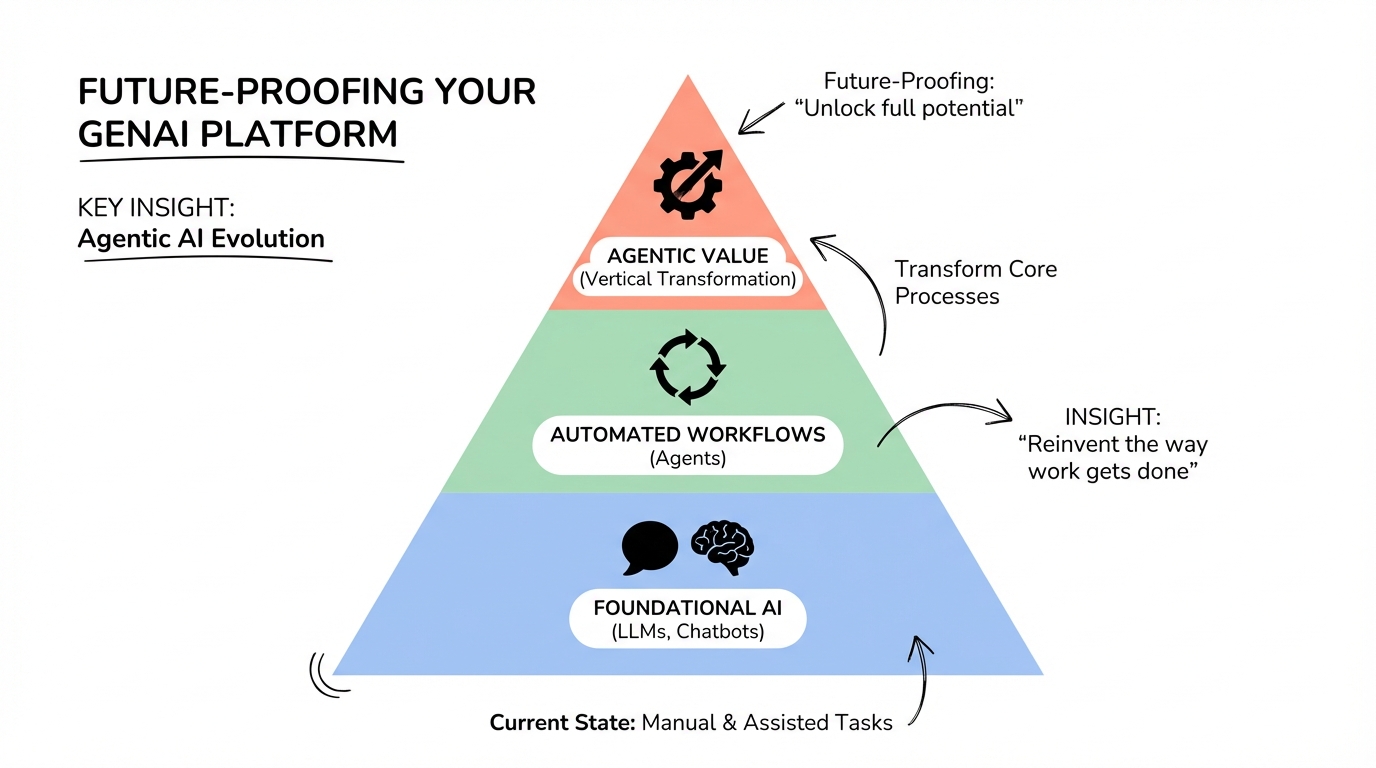
Future-Proofing Your GenAI Platform
Future-Proofing Your GenAI Platform
Emerging Trends to Plan For
Agentic AI Evolution
By automating complex business workflows, agents unlock the full potential of vertical use cases. Forward-looking companies are already harnessing the power of agents to transform core processes. To realize the potential of agents, companies must reinvent the way work gets done—changing task flows, redefining human roles, and building agent-centric processes from the ground up.
Platform Architecture Implications:
- Scalable multiagent orchestration across the enterprise. Enterprises deploying hundreds or thousands of agents require LLMs that can scale efficiently and cost-effectively
- API-first design for agent interactions
- Event-driven architectures for agent coordination
Multimodal AI Integration
IT architectures are also expected to be significantly different, evolving from a traditional application-focused approach to new multiagent architectures. These include new patterns of work, architectural foundations, and organizational and cost structures that change both how teams interact with AI and the role gen AI agents play.
Plan for:
- Vision + text processing pipelines
- Audio generation and processing capabilities
- Video analysis and generation workflows
- Cross-modal search and retrieval
Technology Roadmap Considerations
Short-term (6-12 months)
- Implement semantic caching to reduce costs by 50-70%
- Deploy prompt optimization tools
- Add streaming response capabilities
- Integrate retrieval-augmented generation (RAG) patterns
Medium-term (12-24 months)
- Build agent orchestration capabilities
- Implement fine-tuning pipelines for domain models
- Add computer vision and multimodal processing
- Develop advanced evaluation and red-teaming
Long-term (24+ months)
- Autonomous agent deployment at scale
- Integrated reasoning and planning systems
- Advanced personalization and context management
- Edge AI deployment for latency-sensitive use cases
Vendor Risk Mitigation
Multi-Provider Strategy Benefits:
- While it is tempting to turn to a single provider for all gen AI services, that approach often backfires because the provider's capabilities are not suited to all of a company's specific needs and limit access to best-in-class capabilities. With technology rapidly advancing, it makes more sense to use services offered by providers rather than building them
Risk Mitigation Tactics:
- Standardized API abstractions across providers
- Regular cost and performance benchmarking
- Contractual flexibility for model switching
- Open-source alternatives for critical components
Want more insights?
Subscribe to get the latest articles delivered straight to your inbox.